
Novinky

Etika AI: základní normativní rámec
David Černý
Etika je jednou z nejstarších oblastí systematického přemítání o nás lidech, vztazích, které nás poutají k dalším členům lidské společnosti, a individuálním rozvoji ve ctnostech a dobrém životě. Slovo „etika“ pochází z řeckého substantiva éthos, jenž znamená zvyklost, charakter; přídavným jménem éthikos označovali staří Řekové to, co náleží k etice, morálce či obyčeji.
Primárním objektem zájmu etiky je lidské jednání, které ale neuvažuje v libovolném aspektu, nýbrž pouze a výlučně ve světle dvou vlastností. Naše skutky mohou být správné či nesprávné, v prvním přiblížení můžeme proto říci, že etika je systematickým zkoumáním správnosti a nesprávnosti lidského jednání a faktorů, které tyto vlastnosti určují. Role etiky se však nevyčerpává ve zkoumání jednání, neméně důležitým objektem jejího zájmu jsou i samotní jednající, tedy my lidé (a v posledních letech i AI a roboti). Nejde totiž jen o to, že jednáme správně či nesprávně, ale také – a pro někoho zcela primárně – o to, že si svým jednáním udělujeme určité morálně relevantní vlastnosti, kterým se tradičně říká ctnosti a neřesti.
Naše jednání neovlivňuje jen svět kolem nás, ale mnohdy i nás samotné. Studium pomáhá vytvořit dobré návyky a intelektuální ctnosti, díky nimž je pro nás poznávání snazší a příjemnější. Trénink v nějaké praktické dovednosti z nás může udělat dobré řemeslníky. A cvičení ve hře na klavír zase dobré klavíristy. Jinými slovy, díky jednání – vytrvalému a opakovanému – získáváme určité dovednosti a schopnosti (tradičně se jim říká habity), díky nimž dokážeme vykonávanou činnost provádět snáze a lépe. A totéž platí pro mravní jednání. Jednáme-li opakovaně a vytrvale správně (nebo se o to alespoň systematicky snažíme), vypěstujeme si specifické morální habity, jimž říkáme ctnosti. Těch je celá řada a jejich harmonický rozvoj můžeme spojit s plnohodnotným lidským rozvojem (či jak někteří poeticky říkají, rozkvětem). Člověk, který si vypěstoval mravní ctnosti, je člověkem, který je dobrý a pro něhož je správné jednání přirozené, snadné, bezprostřední a příjemné.
Odtud se dostáváme k důležité a někdy bohužel přehlížené otázce: k čemu nám etika vlastně je? Proč ji potřebujeme? A proč je dobré se nějakou etikou řídit?
Když se zaměříme na první oblast zájmu etiky, lidské jednání, je odpověď snadná. Etika nám pomáhá koordinovat mezilidské vztahy. Člověk dochází naplnění svých přirozených potenciálů ve společenství dalších lidských bytostí. Svým jednáním ovlivňuje životy druhých a druzí svým jednáním ovlivňují jeho život. Etiku můžeme chápat jako nástroj, díky němuž můžeme v lidské společnosti žít takovým způsobem, abychom v něm mohli rozvíjet své potenciály, realizovat své cíle a obecně žít dobré životy. Nebo ještě jinak: etika nám poskytuje určitý normativní rámec umožňující pokojné soužití lidí
ve společnosti.
A kromě toho – a nyní se soustředíme na druhý okruh zájmu etiky – nám etika poskytuje vodítka pro plnohodnotný lidský rozvoj, jehož nedílnou součástí je rozkvět ctností.
Etika a morálka
Není těžké si etiku a morálku splést nebo je dokonce považovat za totéž. Slovo „morálka“ pochází z latinského substantiva mos, moris, které vlastně znamená to samé co řecké slovo éthos. A je pravda, že často mezi těmito slovy nerozlišujeme, hovoříme například o etických teoriích i o morálních teoriích. Navzdory tomu mezi etikou a morálkou existuje velmi důležitý rozdíl. Morálkou většinou rozumíme nějaký systém norem, podle kterého se lidé snaží řídit. Tento systém má celou řadu zdrojů, od evolučního vývoje přes náboženství, kulturu či historii daného společenství. Morálka je tedy v určitém smyslu relativní: morálka jednoho společenství se nějak vyvíjela v čase (například otroctví dnes považujeme za nemorální, ale před nějakou dobou to neplatilo), morálky dvou společenství (ale i dokonce dvou lidí) se mohou více či méně lišit.
Na rozdíl od morálky je etika součást filozofie. Jedná se o vědeckou disciplínu, která zkoumá lidské jednání a hledá teorie jeho správnosti či nesprávnosti a faktorů, které tyto vlastnosti určují. A zabývá se také ctnostmi (neřestmi) a otázkou, jak přispívají k plnohodnotnému lidskému rozvoji a mravnímu jednání. Mnozí zastánci etiky (ale ne všichni) jsou přesvědčení, že zatímco morálka je určitým způsobem nahodilá a její obsahy určuje celá řada faktorů, etika poskytuje teorie správného jednání, které jsou objektivní. Mají tím na mysli,
že pokud nějaká etická teorie identifikuje určitý typ jednání jako nesprávný (např. zotročování, ženskou obřízku či diskriminaci), je skutečně nesprávný bez ohledu na dobu a společenství. Součástí morálního přesvědčení některých lidí je třeba to, že ženská obřízka je správná, etika ale ukazuje, že se musí mýlit. Morální pokrok potom spočívá právě v tom, že se lidská společnost postupně zbavuje nesprávných obsahů svých morálních kodexů a nahrazuje je obsahy prověřenými etickou reflexí.
Etika jen pro lidi?
Z předchozího výkladu se zdá, že etika je o lidech a pro lidi. Není to ale pravda. V první řadě proto, že v dějinách lidského společenství postupně rostlo přesvědčení, že oblast mravního zájmu nemůže být omezena pouze na lidi. Zvířata mohou trpět a neexistuje proto důvod nevěnovat jim patřičnou pozornost v našich etických úvahách. Někteří jdou dokonce tak daleko, že do těchto úvah vpouštějí i rostliny, ekosystémy či dokonce celou planetu. A v posledních několika letech roste počet publikací, které se zamýšlejí nad tím, zda tento rostoucí kruh mravního zájmu nerozšířit i o roboty a systémy umělé inteligence.
Nejde ale jen o rozšiřování morální komunity, tedy třídy bytostí, které musíme v našich etických rozvahách brát v úvahu. Člověk je primárně homo technologicus, jeho přirozenost je spjata s technikou a technikou byla a je utvářena (pomysleme jen na takové věci, jako je oheň, vařená strava, jazyk, knihtisk apod.). My lidé používáme celou řadu prostých i velmi sofistikovaných nástrojů, technických artefaktů. Může se zdát, že pro etiku tím žádný problém nevzniká; z jejího pohledu je asi jedno, jestli něco správného (nesprávného) uděláme holýma rukama nebo pomocí nějakého nástroje. V této perspektivě se může zdát, že role techniky (a mezi technické artefakty řadíme i AI a roboty) je čistě instrumentální. Nebo jinak, technika je morálně neutrální (není ani dobrá, ani špatná), správné či nesprávné je pouze její využívání člověkem.
Tato zjednodušující koncepce techniky má však dnes jen pramálo zastánců. Jistě, je pravda, že lidé mohou použít sekeru k sekání dřeva, ale (bohužel) i k tomu, aby někoho zavraždili. Podle instrumentalismu je to ale člověk a jeho použití sekery, nikoli sekera samotná, kdo může mít dobré i špatné důsledky pro ostatní. Tak jednoduché to ale není. Ukazuje se totiž, že technika morálně neutrální není a dobré i špatné důsledky může mít již samotná existence nějakých technických artefaktů.
Auta nás převážejí z bodu A do bodu B, současně ale mění tvář krajiny a měst a nutí nás přizpůsobovat jim své životy. Mobilní telefony a jejich aplikace umožňují celou řadu forem komunikace, současně ale ovlivňují naše životy, soustředění a pozornost, a redefinují a mění třeba i formy setkávání a interakcí. Žárovka přinesla světlo do našich domácností, kromě toho ale také narušila naše přirozené rytmy spánku a bdění a umožnila unifikaci lidského života (kdy vstáváme, kdy pracujeme, kdy odpočíváme, kdy spíme). Etika techniky se proto soustředí na způsoby, jakými se technické artefakty staví mezi nás a svět, a spoluurčují tak nejen formy našeho vztahování se k němu (v poznání i jednání), ale i kontury lidské přirozenosti (co znamená být člověkem) a pospolitosti. Současná etika se tedy nesoustředí pouze na lidské jednání, ale také na důsledky existence a využívání techniky, včetně systémů umělé inteligence a robotů.
Rozdělení etiky
Současná etika se většinou dělí do čtyř oblastí:
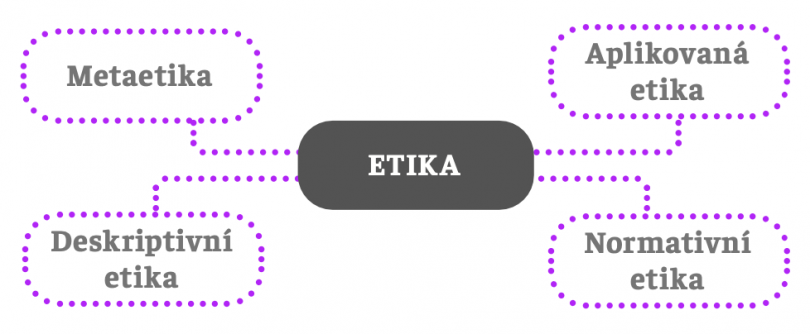
Metaetika je poměrně složitá subdisciplína etiky, kterou se zde naštěstí nemusíme zabývat. Postačí jen vědět, že se věnuje jazyku etiky a klade si otázky jako „mají výroky etiky pravdivostní hodnotu?“, „existují morální vlastnosti?“, „jak poznáváme morální vlastnosti?“ apod. Normativní etika je teoretickým jádrem etiky a zabývá se tvorbou etických teorií, tj. teorií správnosti a nesprávnosti a faktorů, které tyto vlastnosti ovlivňují. Deskriptivní etika popisuje morálku a konečně aplikovaná etika se pokouší aplikovat teoretické etické poznání na vybrané třídy problémů, například etika životního prostředí, etika klimatické změny, práv zvířat, medicíny, výzkumu či techniky.
Etika umělé inteligence
Umělá inteligence ve svých různých podobách je takřka všudypřítomná a dobývá se do všech oblastí lidské existence. Někteří autoři ji proto přirovnávají k objevu a využívání elektřiny, jiní o ní hovoří jako o ohromné vlně, která se postupně přelévá celou lidskou společností. Pozitivní potenciál AI je jednoduše ohromující: může prudce urychlit vědeckotechnický pokrok, generovat blahobyt, výrazně zlepšit kvalitu i délku lidského života. Mnozí autoři se ale obávají, že tato pozitiva mohou být snadno převážena negativy. AI může být dobrý sluha, ale velmi špatný pán. Nemusíme si hned myslet, že nás AI z nějakého důvodu vyhubí. Elektřina je také prakticky všudypřítomná, a kdyby došlo k jejímu delšímu globálnímu výpadku, byla by naše civilizace v ohrožení. Podobně všudypřítomná začíná být i AI, a pokud by její rozhodování nebylo v souladu s lidskými hodnotami, měli bychom velký problém.
V posledních letech se proto nepřekvapivě dostala do popředí zájmu odborníků etika AI, kterou můžeme chápat jako aplikovanou etiku, tj. snahu vztáhnout etické teorie na systémy AI, jejich existenci, rozhodování, jednání a využívání lidmi. Hlavním cílem etiky AI je vytvořit normativní (závazný) rámec regulace AI, aby sloužila ve prospěch lidí, společnosti i životního prostředí.
Etika AI. Ale jaká etika?
Již staří Řekové si velmi dobře uvědomovali, že etika je disciplína z povahy svého objektu zájmu velmi nesnadná. Soustřeďuje se totiž na nesmírně komplexní a těžko předvídatelnou oblast: lidské jednání, lidskou společnost a lidské výtvory. Není proto překvapivé, že etika – akademická disciplína – není zcela jednotná. Existuje několik hlavních etických teorií, které mají celou řadu variant. Mnohdy se na závěrech shodují, často ale také ne, kromě toho nabízejí jiná vysvětlení pro to, že nějaké jednání je či není správné nebo nesprávné. A v etice, která si klade za cíl regulovat jednání lidí i strojů, jsou závěry stejně důležité jako důvody, které k nim vedou. Etika nedisponuje stejnou vědeckou metodologií jako přírodní vědy, nemá k dispozici smyslově vnímatelnou realitu, která by mohla být východiskem jejího zkoumání a poskytovala jejím závěrům empirické verifikátory (či falsifikátory). Kvalita a přijatelnost etických teorií a jejich závěrů stojí a padá s kvalitou argumentů a důvodů.
Aplikovaná etika aplikuje etické teorie na určité oblasti. Chceme-li se zabývat etikou AI, musíme mít k dispozici nějakou etickou teorii a dobré poznání dané oblasti (AI). Jaká by to ale měla být? Snad každý etik se drží nějaké etické teorie, kterou považuje za lepší než ostatní, my zde ale stojíme před praktickou výzvou. AI a její systémy jsou již mezi námi a ovlivňují naše životy. Její pozitivní i negativní potenciál je ohromující a my lidé nemůžeme složit ruce do klína a čekat, jak se věci vyvrbí. Musíme být proaktivní a AI regulovat, aby nám prospívala a abychom eliminovali její negativní potenciál či ho alespoň snížili na rozumnou a tolerovatelnou hranici.
Nebudu se zde proto zabývat etikou AI v celé její šíři, nebudu zde popisovat všechny možné etické přístupy ani současný stav odborné diskuze, dokonce se ani nepokusím předložit svou preferovanou etickou teorii a aplikovat ji na AI. Mé záměry jsou mnohem skromnější a praktičtější. V celé řadě národních i mezinárodních dokumentů zabývajících se etikou a regulací AI se prosadil určitý přístup k ní. Představím ho zde a ukážu, jak jej lze využít například společnostmi, které hledají normativní východiska pro tvorbu etických kodexů a vnitřních firemních politik.
Tři základní pilíře
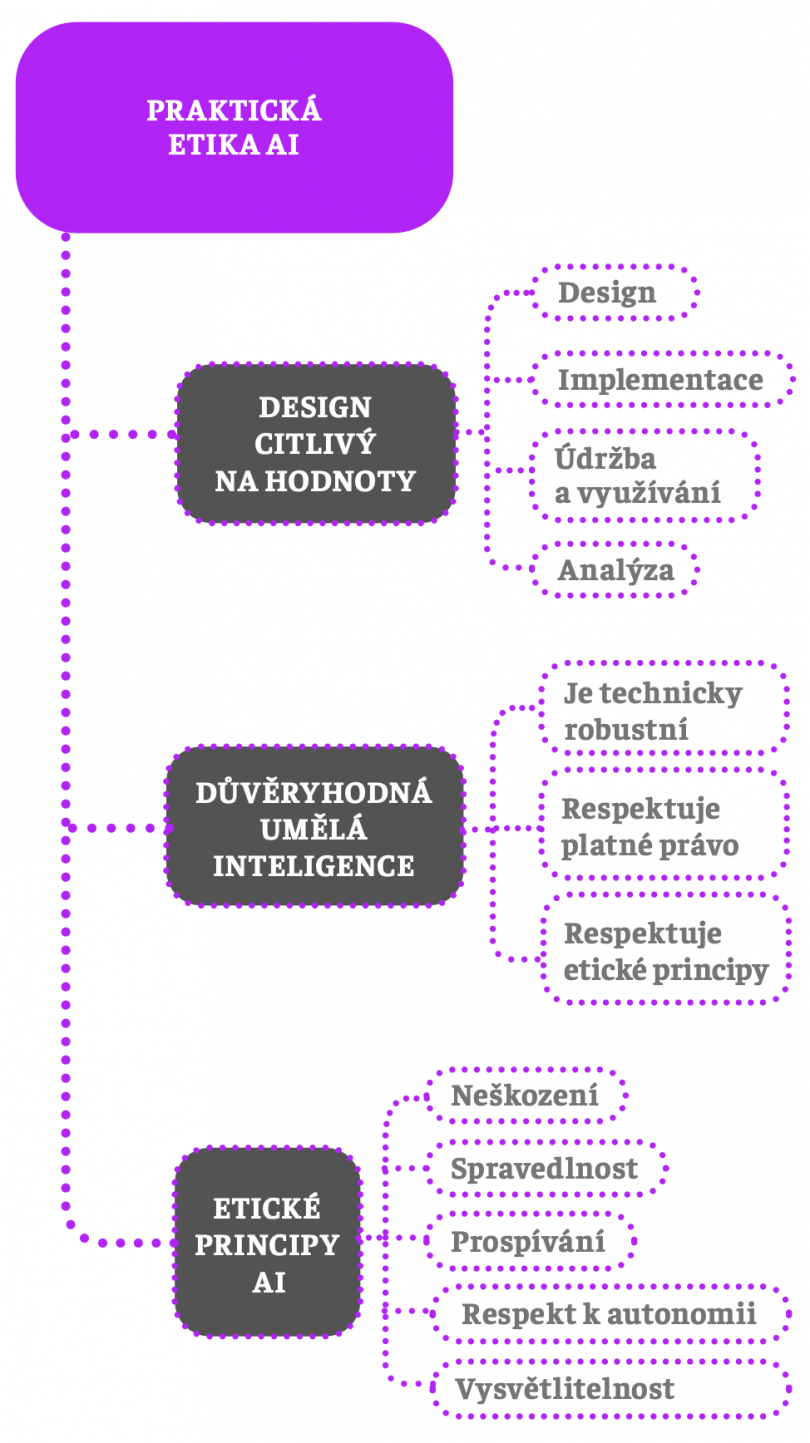
Zkusme se na chvilku vžít do role odborníka, který je pověřený vytvořením základního konceptuálního a normativního rámce pro regulaci AI. Jak by měl postupovat a jaké poznatky, koncepty a teorie bude pro svou činnost potřebovat? Úplným minimem je mít k dispozici nějakou základní teoretickou jednotící koncepci, prakticky aplikovatelné etické principy a samozřejmě také nějakou metodologii:
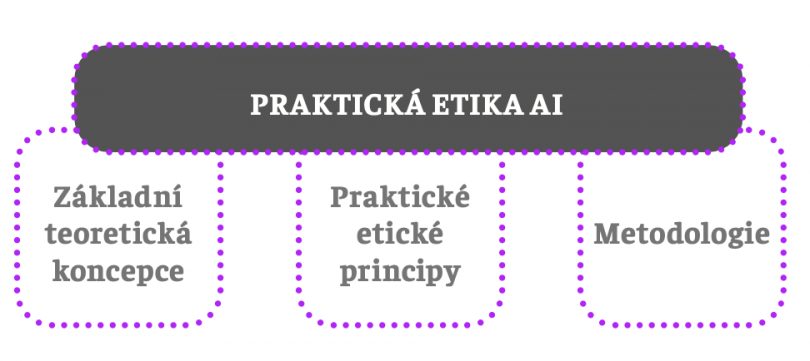
Základní teoretická koncepce
Za základní jednotící teoretickou koncepci můžeme považovat důvěryhodnou umělou inteligenci. Definovat důvěryhodnost není jednoduché. Jedná se o komplexní pojem, který zahrnuje celou řadu složek, například integritu, spolehlivost či transparentnost. Někdo (nebo něco) je pro nás důvěryhodné, pokud se chová eticky správně, konzistentně, ve shodě se svými sliby a předsevzetími, jednoduše někdo, komu můžeme věřit, protože víme, jak se bude chovat, a víme, že se bude chovat správně a nijak nám neublíží.
Pojem důvěryhodnosti lze velmi dobře aplikovat také na systémy AI. Intuitivně je důvěryhodná AI taková, která se chová předvídatelně, správně a spolehlivě. V praxi to znamená, že systémy AI musí mít celou řadu vlastností a splňovat určité požadavky, aby se chovaly odpovídajícím způsobem, a umožnily tak vznik pouta důvěry mezi ní a námi. Tyto vlastnosti a požadavky spadají do tří kategorií:
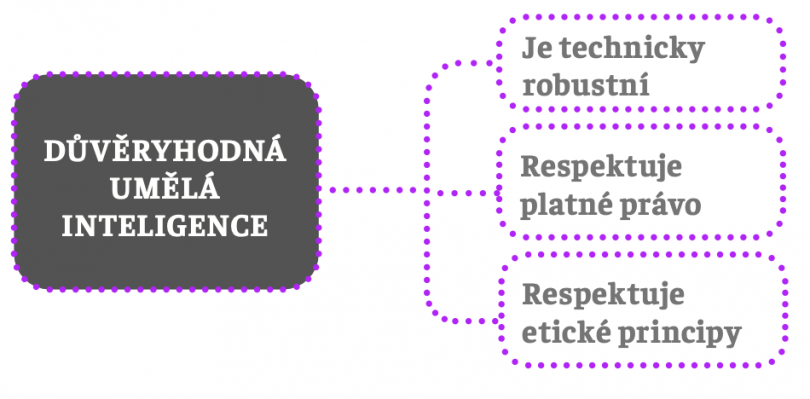
Žádná z kategorií nezahrnuje triviální vlastnosti a snadno splnitelné požadavky. Důvěryhodná AI (dále jen DAI) musí respektovat platné právo. Neexistuje však žádná snadno implementovatelná procedura, která by splnění tohoto požadavku zajistila. Právo se aplikuje na komplexní a složitý systém společenských vztahů a jeho dobrá aplikace vyžaduje poznání kontextu, interpretaci a celou řadu praktických dovedností.
Neméně problematická je aplikace etických principů (viz níže). I když si vybereme obecné a dostatečně jednoduché principy, opět je musíme aplikovat na složité systémy zahrnující lidské hodnoty, práva, ale také přesvědčení, očekávání, tužby a preference. Kromě toho se tyto principy v praxi snadno dostávají do sporu a neexistuje žádná všeobecně přijímaná procedura, jak napětí mezi principy efektivně řešit.
Pojem DAI zahrnuje také specifické technické požadavky kladené na systémy AI. Mezi nejdůležitější patří transparentnost a s ní spojená vysvětlitelnost, dále spolehlivost, bezpečnost a kontrolovatelnost. V případě moderních systémů AI se však ukazuje, že – minimálně za současného stavu vědeckotechnického poznání – jsou mnohé z těchto vlastností v těchto systémech nedosažitelné. Hluboké neuronové sítě nejsou transparentní a vysvětlitelné, nelze proto určit, zda jsou bezpečné, spolehlivé a kontrolovatelné.
Přesto přese všechno je koncepce DAI hodnotná a důležitá, protože nastavuje důležitý ideál, na jehož dosažení by se měl výzkum na poli AI zaměřit. A pokud by se to ukázalo jako nemožné, poskytuje dobré teoretické pozadí pro další praktické úvahy, např. zda takové systémy AI vůbec používat, v jakých oblastech to přípustné je, v jakých rozhodně není apod. I neúspěch ve snaze o dosažení nějakého ideálu může mít důležité praktické důsledky, jejichž finalitou je primárně ochrana lidských hodnot, kvality života a společného soužití.
Etické principy
Druhou integrální součástí pojmu DAI je respekt k etickým principům. Praktická etika a snaha o regulaci AI se ocitla ve stejné situaci jako lékařská etika v 70. letech minulého století. Medicína se prudce rozvíjela, vědeckotechnický pokrok přinášel celou řadu benefitů, ale současně vytvářel nové situace, které vyžadovaly etickou rozvahu a konkrétní řešení. Například objev mechanického plicního ventilátoru umožnil zachraňovat lidské životy, ale současně stavěl lékaře před otázku, zda a za jakých podmínek je možné tuto podporu života ukončit (a nechat pacienta zemřít).
Stejně jako dnes, i tehdy existovala celá řada etických teorií. Zdravotníci však nepotřebovali teorie, ale praktická vodítka, podle nichž by se mohli ve své praxi efektivně rozhodovat. V tomto kontextu spatřila světlo světa etická teorie známá jako principlismus. Její název pochází z toho, že jejím základem jsou čtyři obecné etické principy, které mají ve svém souhrnu poskytnout požadovaná praktická normativní vodítka.
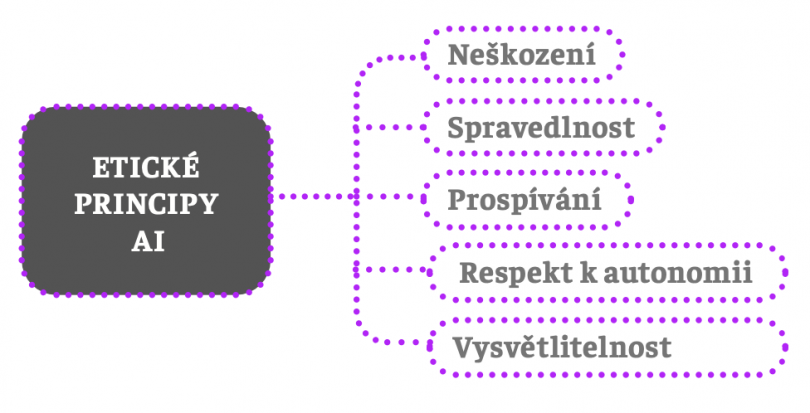
Jedná se o následující čtyři principy (známé také jako principy lékařské etiky):
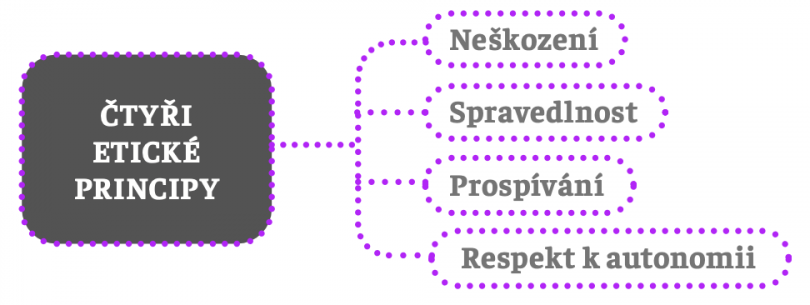
V literatuře se také hovoří o principu prospívání (beneficence), principu neškození (non-maleficence), principu respektu k autonomii a konečně principu spravedlnosti. Všechny čtyři mají stejnou normativní sílu, což znamená, že mezi nimi neexistuje žádná hierarchie; všechny jsou stejně důležité a závazné.
Ve velmi obecné, abstraktní rovině se zdá být aplikace těchto principů na AI poměrně snadná. Princip prospívání říká, že AI má lidem (zvířatům, životnímu prostředí) prospívat, princip neškození zapovídá působit újmu, princip respektu k autonomii vyjadřuje požadavek, aby lidské autonomní volby a jednání nebyly AI omezovány, a konečně princip spravedlnosti se hlásí k rovnosti všech lidí a zakazuje jakoukoli formu diskriminace. Uvidíme později, že toto zdání je velmi chybné.
Etika AI se však nespokojuje se čtyřmi principy lékařské etiky. Představme si například, že se proti nám vede soudní proces, a nakonec je vynesený rozsudek. Pro nás, naše advokáty, ale vlastně i pro samotný právní systém a veřejnost je velmi důležité vědět, jaké důvody vedly soudce k tomu, že dospěl k nějakému verdiktu a uložil trest. Je to důležité pro nás, protože chceme vědět (a máme právo vědět), jaké argumenty a důvody rozhodly o našem osudu. Je to důležité pro naše advokáty, protože tak mají možnost nás hájit (a tím i spravedlnost). Je to podstatné pro právní systém, protože je důležité vědět, že respektuje nestrannost, vládu práva, spravedlnost a rovnost. A samozřejmě je to důležité i pro veřejnost, jejíž fungování je právním systémem výraznou měrou regulováno a důvěra v nestranný a spravedlivý právní systém je důležitou hodnotou demokratických společností.
A nyní si představme, že důvody soudcova rozhodnutí jsou skryty (nejsou transparentní), takže je nelze vysvětlit, pochopit, podrobit kritice a případně i zvrátit. Jednalo by se o radikální zásah do základních lidských práv a pošlapání celé řady lidských a společenských hodnot. Není proto překvapivé, že vysvětlitelnost se vyžaduje i od AI, zvláště uvědomíme-li si opět její všudypřítomnost a nebývalé možnosti zasahovat do našich životů. Svěřujeme-li AI stále více rozhodnutí – zvláště těch důležitých – měla by být vysvětlitelná.
Princip vysvětlitelnosti je poslední princip etiky AI, jejíž výsledná podoba je následující:
Byť je smysl a význam tohoto principu pro etiku a regulaci AI pochopitelný, nelze zastírat fakt, že mnohé systémy AI transparentní a vysvětlitelné nejsou a navzdory pokračujícímu výzkumu na poli vysvětlitelné AI (XAI) zatím není žádné uspokojivé řešení v dohledu.
Design citlivý na hodnoty
Posledním pilířem praktické etiky AI je určení nějaké metodologie zavádění a sledování systémů AI a jejich fungování. Důležitým východiskem této metodologie je důrazně proaktivní přístup: hodnotové úvahy nepřicházejí ex post, až poté, co nějaký systém AI existuje, ale měly by doprovázet jeho vývoj, návrh, implementaci v praxi a využívání. Design citlivý na hodnoty představuje ztělesnění tohoto proaktivního přístupu k návrhu AI v praxi a s ním spojených hodnotových a etických rozvah.
V rámci designu citlivého na hodnoty je možné rozlišit čtyři navazující fáze:
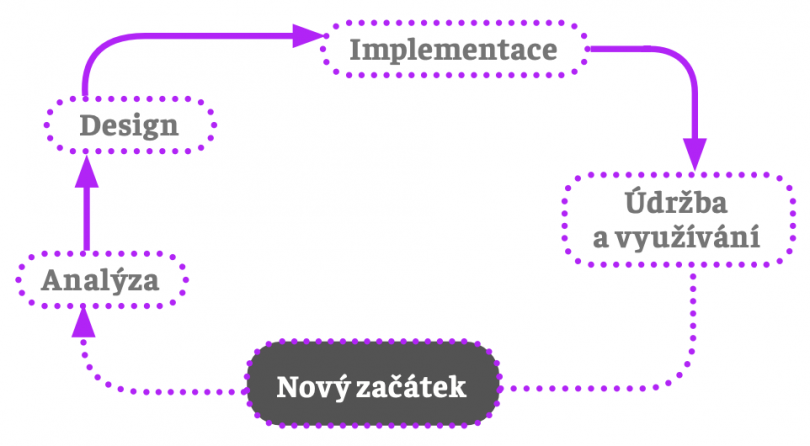
Představme si nejdříve, že systém AI ještě neexistuje a je teprve třeba ho vytvořit. V rámci analýzy je třeba položit si celou řadu otázek: proč chceme AI vytvořit, jakou roli bude hrát ve společnosti, jaké úkoly bude plnit, jaké hodnoty by měla ztělesňovat a zachovávat, jaké benefity slibuje, s jakými riziky je spojena, jaký segment populace má potenciál ovlivnit, jak konkrétně by měla respektovat etické principy, jakým způsobem je možné identifikovat rizika a jejich vážnost, jaké mechanismy jejich eliminace či alespoň zmírnění existují (a které z nich je možné přijmout a využít), jak by se měla rozhodovat apod. Odpovědi na tyto otázky nemusí být snadné najít, jsou ale zcela zásadní a hrají důležitou roli v návrhu AI. Nejde jen o to, aby AI plnila úlohu, pro niž byla stvořena (např. diagnostikovala choroby, generovala obrázky, rozhodovala o poskytování půjček atd.), ale aby ji plnila dobře: respektovala platné právo, lidské hodnoty, etické principy a byla dostatečně technicky robustní, aby byla bezpečná, spolehlivá a (pokud možno) transparentní a vysvětlitelná. Jinak řečeno, cílem je vytvoření důvěryhodné umělé inteligence.
Po návrhu a vytvoření AI následuje uvedení do provozu, které ale není samozřejmé. Splnit všechny požadavky spojené s konceptem DAI není možné, lze se k tomu ale přiblížit. Další záleží na kontextu. Některé vyžadují co největší blízkost k ideálu DAI, a pokud se k němu nepodaří dostatečně přiblížit, neměla by se v něm AI využívat. Například systém COMPAS se využívá u soudů k predikci recidivy a mnohé soudy k těmto predikcím ve svých rozhodnutích přihlížejí. Jedná se však o systém, který není transparentní a není možné vysvětlit, jak ke svým rozhodnutím dochází (víme ale, že jsou často diskriminační). COMPAS se využívá v kontextu (aplikace práva), který vyžaduje vysokou míru blízkosti k plnému ideálu DAI. Jelikož ho však v podstatných bodech nedosahuje (transparentnost, vysvětlitelnost, spravedlnost), neměl by se vůbec používat, a pokud se již někde využívá, měla by tato praxe okamžitě skončit.
Čtvrtou fází je využívání AI a údržba. Cyklus se zde vrací na samotný začátek, protože fungování AI a její důsledky je třeba neustále sledovat. Existuje pro to celá řada důvodů: potřeba vyhodnocování efektivity mechanismů kontroly rizik; fakt, že vzhledem ke složitosti oblasti aplikace AI není snadné předvídat všechna rizika a negativní dopady; u některých předvídaných dopadů se nemusí podařit odhadnout jejich míru a ty mohou být vážnější, než se předpokládalo. Analýza má za úkol popsat a zhodnotit důsledky využívání AI, navrhnout možné úpravy, posílit mechanismy eliminace a zmírňování rizik a v případě potřeby navrhnout nové. Celý proces pokračuje až k úvaze, zda je možné AI nadále využívat a v průběhu tohoto využívání se opět vrací do fáze analýzy.
Konceptuální, normativní a metodologický rámec etiky umělé inteligence je v základních rysech kompletní:
A jak dále?
Vytyčení výše uvedeného rámce etiky AI je pouhým začátkem. Ve skutečnosti před námi stojí celá řada dalších výzev a nemusí být vůbec jednoduché najít jejich řešení. Popíšu zde jen některé z nich.
Etické principy, jimiž by se AI měla řídit, jsou vcelku snadno popsatelné v obecné, abstraktní rovině, jejich praktická aplikace však tak jednoduchá být nemusí. První princip požaduje, aby systémy AI prospívaly lidem a společnosti, celou řadu otázek však nechává nezodpovězených. Co přesně znamená, že AI prospívá? Existuje nějaká definice prospívání? Je na této definici shoda, která by umožnila její aplikaci v různých, často velmi odlišných, kulturních a náboženských kontextech? Podobné otázky si můžeme klást i u dalších etických principů. Co je to například újma, jejíž působení druhý princip zapovídá? A jaké formy újmy existují? Jsou všechny formy újmy stejně závažné? A je vůbec možné srovnávat závažnost různých forem újmy (například fyzické a psychické)?
Tyto problémy neznamenají, že je projekt etiky AI v troskách. Ukazují však, že vytyčení obecného etického rámce etiky AI – jaký nacházíme v celé řadě mezinárodních dokumentů – není dostačující. Od tohoto rámce k praktické aplikovatelnosti a aplikaci je ještě dlouhá cesta. Mohli bychom si pomoci například tak, že se zaměříme na konkrétní využití AI a pokusíme se odpovědět na výše položené otázky nikoli pro AI obecně, ale pouze pro tuto doménu využití.
Pro každou doménu, v níž budeme využívat AI, můžeme určit doménově specifické hodnoty, které nám umožní konkretizovat aplikaci etických principů. Například v případě autonomních vozidel to může být bezpečnost posádky a provozu, plynulost provozu, nižší emise a zátěž pro životní prostředí, zvýšená dostupnost dopravy pro vyloučené skupiny apod. Újmu lze potom situovat do jasně vymezených a pro provoz vozidel typických kategorií, např. újma na majetku, zdraví a životech. Odlišné hodnoty budeme zřejmě identifikovat u ošetřovatelských či společenských robotů, jiné u systémů online identifikace a další zase u generátorů obrázků.
Ale ani když se nám podaří určit tyto doménově specifické hodnoty (a k tomu nás metodologie designu citlivého na hodnoty vybízí), nemáme zdaleka vyhráno. Není obtížné identifikovat tři hlavní kategorie újmy v případě provozu autonomních vozidel, jakým způsobem ale budeme tyto rozdílné typy újmy srovnávat? Měli bychom například vytvořit nějakou hierarchii, která reflektuje vážnost újmy? Mohli bychom pak vcelku plausibilně tvrdit, že újma na životě je vážnější než újma na zdraví a újma na zdraví je vážnější než újma na majetku. Z této hierarchie by už bylo možné odvodit jasná pravidla distribuce újmy: pokud se autonomní vozidlo ocitne v situaci, kdy musí distribuovat újmu, mělo by vždy chránit životy, poté zdraví a nakonec majetek. Kdyby například mělo volbu „usmrtit chodce A“, nebo „zranit posádku vozidla“, mělo by vždy volit druhou možnost.
Tento jednoduchý etický systém minimalizace újmy je v mnoha ohledech intuitivně přijatelný, není ale obtížné vytvořit scénáře, v nichž si nebudeme jistí, že je korektní. Mělo by vozidlo způsobit jakoukoli majetkovou škodu, jen aby zabránilo triviálnímu zranění? A je vždy lepší zachránit lidský život
i za cenu vážného zranění více jedinců?
Jinou možností by mohlo být najít nějakou společnou hodnotu, která by umožnila srovnávání újmy napříč kategoriemi. Existují teorie, které nám to umožňují, ale ani v tomto případě nebude řešení prosté problémů. Řekněme, že touto společnou „měnou“ je nějaké X (pro ilustraci není nutné X blíže specifikovat). Smrt může mít hodnotu nX, určité zranění mX a majetková újma sX. Etika minimalizace újmy by potom mohla mít následující podobu: v kolizní situaci distribuuj újmu tak, aby celková hodnota újmy byla minimální. Smíříme se ale s tím, že když bude hodnota smrti jednoho člověka o jediný bod X nižší než součet negativních hodnot zranění, obětuje vozidlo lidský život?
Nabízí se ještě jiná možnost. Možná by nejlepším řešením bylo zakázat autonomním vozidlům činit takto závažné volby a povolit jim jedinou možnost: pokud se dostaneš do kolizní situace, nerozhoduj o distribuci újmy, neměň směr jízdy, pouze intenzivně brzdi. Toto řešení má zdánlivou výhodu v tom, že nás zprošťuje povinnosti obtížných etických rozvah. Je to ale výhoda pouze zdánlivá, nejméně ze dvou důvodů. Prvním z nich je to, že z empirických výzkumů víme, že toto řešení se lidem vůbec nezamlouvá. Preferují, aby se vozidla nějak rozhodovala, dokonce preferují, aby se rozhodovala tak, aby minimalizovala újmu. A druhým důvodem je to, že toto řešení v praxi znamená, že autonomní vozidla budou působit více újmy, než by bylo nutné. Kdyby se například dostalo do situace, kdy lze volit mezi A: prudce brzdit a ohrozit dvě děti na přechodu, B: zahnout doprava a ohrozit řidiče, není volba „pouze brzdi“ pro většinu lidí přijatelná. Kdyby vozidlo neubrzdilo a narazilo do dětí, vyvolalo by to intenzivní negativní emoce a narušilo možnost vzniku pouta důvěry mezi lidmi a autonomními vozidly.
Tyto problémy se týkají distribuce újmy, tj. aplikace principu neškození, a vidíme, že to není vůbec jednoduché. Do sporu se ale často dostává více etických principů. Představme si například systém AI, který má rozhodnout o tom, zda má onkologický pacient podstoupit chemoterapii, či se spíše svěřit paliativní péči. Chemoterapie má potenciál pacientovi prospět (uzdravit ho, zlepšit symptomy, prodloužit mu život), současně ale víme, že má celou řadu negativních účinků. Ve hře jsou tedy principy prospívání a neškození; první říká, že chemoterapie je přípustná pouze tehdy, může-li pacientovi prospět, druhý zapovídá působení újmy. Je zjevné, že jsou oba principy ve sporu a je třeba nějakým způsobem vyvažovat. Žádná obecná a snadno aplikovatelná metoda vyvažování však neexistuje. A celá situace se výrazně komplikuje tím, že vyvažování prospěchu a újmy není nějakou čistě medicínskou, „objektivní“ záležitostí. Do rozhodovacího procesu totiž vstupuje samotný pacient se svými hodnotami, preferencemi, představami o kvalitním životě apod. Jinými slovy, přípustnost chemoterapie nezávisí pouze na medicínských faktorech, ale také na hodnotovém systému pacientů a jejich očekáváních. U některého pacienta mohou být nastaveny tak, že je chemoterapie přípustná i tehdy, kdy způsobí vážnější a těžko snesitelné vedlejší důsledky a naděje na úzdravu není příliš vysoká, u jiného to platit nemusí.
Etické principy se aplikují v komplexních situacích a jejich aplikace není určena pouze „objektivními“, dobře zjistitelnými a naučitelnými faktory, ale také faktory subjektivními a kontextově závislými. Pro AI nemusí být vůbec snadné tyto principy aplikovat (není to snadné ani pro člověka) v různých kontextech a na odlišné subjekty. A vzhledem k tomu, že celá řada empirických výzkumů ukazuje, že máme tendenci soudit umělé systémy mnohem přísněji než nás lidi, mohla by rozhodnutí AI lidmi vnímaná jako nesprávná vést k celé řadě negativních důsledků, jež by v posledku ohrozily vnímání AI jako důvěryhodné.
Je tedy zjevné, že od etické teorie k její dobré aplikaci vede dlouhá cesta lemovaná celou řadu výzev a problémů. Věřím ale tomu, že když se budeme soustředit na konkrétní typy AI a domény jejich využívání, dokážeme identifikovat příslušné doménově specifické hodnoty, blíže vymezit význam etických principů v těchto doménách a najít i přijatelná konkrétní pravidla rozhodování. Bude to však vyžadovat soustředěné úsilí a reflexi mezioborových týmů odborníků a také celospolečenskou diskuzi o obavách a očekáváních,
která si s AI spojujeme.
Literatura
Anderson, M., Anderson, S. L. Machine Ethics. Cambridge: Cambridge University Press, 2011.
Blackman, R. Ethical Machines. Boston, Mass.: Harvard Business Review Press, 2022.
Dignum, V. Responsible Artificial Intelligence. Cham: Springer, 2019.
Floridi, L. The Ethics of Artificial Intelligence. Principles, Challenges, and Opportunities. New York: Oxford University Press, 2023.
Friedman, B., Hendry, D. G. Value Sensitive Design. Cambridge, Mass.: The MIT Press, 2019.
Liao, M. S. (ed.). Ethics of Artificial Intelligence. New York: Oxford Iniversity Press, 2020.
Lin, P., Jenkins, R., Abney, K. (eds.). Robot Ethics 2.0. New York: Oxford University Press, 2017.
Shadbolt, N., Hampson, R. As If Human. Ethics and Artificial Intelligence. New Haven: Yale University Press, 2024.
Taebi, B. Ethics and Engineering. Cambridge: Cambridge University Press, 2021.
---
Původně vyšlo v Proč se nebát umělé inteligence. Jota, Praha 2024. Autoři knihy Proč se nebát umělé inteligence? nabízejí střízlivý a odborně podložený pohled na současný stav a perspektivy umělé inteligence (AI). Čtenář se ve srozumitelné podobě dozví, na jakých technologických základech AI stojí, jaká je její historie a jak probíhá zpracování přirozené řeči ve velkých jazykových modelech. Kniha rovněž ukazuje, jak aplikace AI už dnes slouží v průmyslu, zdravotnictví, robotice či v oblasti kybernetické bezpečnosti a jak konkrétně je možné AI využít například ve státní správě či ve službách. Řada příspěvků je věnována filozofickým úvahám o roli a možnostech umělých strojů, etice a právu při jejich využívání.


Pečovatelští roboti, emoce a reciprocita
David Anthony Procházka, Juraj Hvorecký
Jeden z mála významných výzkumů veřejného mínění, který se věnoval vztahu veřejnosti k robotům, byl Eurobarometr 382: Public attitudes towards robots. Přestože robotika je klíčovou technologií pro budoucí konkurenceschopnost Evropy, průzkum ukázal, že veřejnost tuto technologii vnímá problematicky. Naneštěstí je vnímání robotů často ovlivněno mylnými představami a emocionálními obavami. Aby se zlepšilo vnímání robotů a zvýšila se jejich přijatelnost napříč populací, je nutné lépe porozumět postojům veřejnosti k této technologii. Za tímto účelem se Eurobarometr ptal na obeznámenost s technologií, osobní zkušenosti s roboty a konkrétnější postoje k nim. Průzkum rovněž zkoumal různé oblasti využívání robotů a poukázal na obory, v nichž by podle názoru občanů EU měli být roboti upřednostňováni, nebo naopak zakázáni. Dotazování rovněž zkoumalo, do jaké míry je u některých úkolů přijatelné, aby je prováděli roboti. Výsledky Eurobarometru 382 jsou poměrně alarmující, ale představují důležitý signál, který by měl přivést společnost k zamyšlení nad postoji k technologickému pokroku a jeho využití v nejrůznějších sférách našeho života. Zjištění, že 23 % respondentů vykazuje celkově negativní postoje vůči robotům, poukazuje na reálné obavy a otázky ohledně role technologie a automatizace v naší společnosti. Ještě více znepokojující je skutečnost, že přes 60 % dotázaných podporuje zákaz použití robotů v jakémkoliv vztahu s dětmi, starobními důchodci a zdravotně postiženými. To znamená, že existuje výrazná nedůvěra ve schopnost strojů a robotů poskytovat patřičnou péči a empatii. Tohle zjištění může dramaticky ovlivnit budoucí technologizaci zdravotního a sociálního sektoru.
Nástin problematiky
Nízká akceptace robotů v oblasti péče může být kontraproduktivní, jelikož současně musíme brát vážně demografické změny a při nárůstu počtu opatrovaných osob, kombinovaném se současným poklesem porodnosti není moc prostor pro emocionálně vyhrocené reakce. Může se stát, že se ocitneme v situaci, kdy už nebude záležet jenom na názorech a přáních veřejnosti, ale okolnosti nás donutí k přijetí nepopulárních opatření i v této oblasti. Například v Německu se očekává, že do roku 2050 bude více osmdesátiletých lidí než padesátiletých. Trend demografického stárnutí společnosti znamená, že neustále vzrůstá potřeba péče a podpory pro starší generace, a to v celém (minimálně) evropském prostoru.
Eskalace situace v oblasti pečovatelství je patrná již nyní, kdy kapacita péče není personálně zajištěna a často je nedostupná i z finančního hlediska. Počet lidí poskytujících péči na jednoho pečovaného v poměru pořád klesá, což představuje značnou výzvu pro společnost, která nicméně není vybavena prostředky, jakými by tuto situaci mohla alternativně řešit. Je tedy zásadní, abychom se zaměřili na nalezení způsobů, jak efektivně integrovat technologii do péče o zranitelné skupiny obyvatelstva, aniž bychom ztratili lidskou dimenzi a empatii, kterou tato péče vyžaduje.
Výsledky Eurobarometru 382 naznačují potřebu hlubšího dialogu o budoucnosti technologie a jejího místa v péči o stárnoucí populace a další zranitelné skupiny obyvatelstva. Vůbec nepopíráme, že je důležité brát v úvahu různé pohledy a obavy společnosti, abychom mohli najít vyvážený a udržitelný přístup k problematice. Jedním ze způsobů, který může změnit přístup lidí k robotům, je jejich postupné operativní zavádění do praxe, a to v malé, ale kontrolované a bezpečné míře, kdy i zarytí skeptici zažijí ulehčení situací díky využití asistivních, opatrovatelských nebo pečujících robotů. Následně by se názor většinové společnosti mohl obracet ve prospěch využívání nových technologií, jako jsme tomu byli svědky v minulých dobách u zavádění převratných technologií, jako byly pára, žárovka nebo internet.
Trochu překvapivě jsou zjištěné výsledky i ukázkou nedostatečně kvalitní vědecké práce, která následně ovlivňuje tvorbu legislativy a direktiv EU a následně i transpozici národních politik. Sami vědci se v textu Eurobarometru 382 přiznávají, že museli otázky zkrátit a zjednodušit oproti původně předpokládanému výzkumu, aby si zajistili velký response rate (n více než 26 000, což je vskutku impozantní velikost zkoumaného vzorku!). Pod pokládanými otázkami si tak ale lze představit příliš mnoho: vždyť i ústřední pojem robot není respondentům jednoznačně vysvětlen. Lze si tak lehce představit (zřejmě především u starší generace), že při čtení otázek mají před očima Terminátora T100, jehož hlavním cílem je ubližovat lidem. Takové představy se zásadně liší od pozadí obdobných otázek, které byly použity například ve výzkumech v Japonsku, kde je robot běžnou populací vnímán jako něco přínosného, povšechně kamarádského a sestrojeného se záměrem pomáhat lidstvu. Člověk a robot jsou zde vnímáni jako partneři a otázky kladené v Eurobarometru nejsou bez přihlédnutí k širšímu kulturnímu rámci příliš vhodné. Samotný dotazník by mohl tento problém vysvětlit nebo překlenout například obrázkem, který naznačuje nejen přívětivý design asistivního robota, ale i anatomické robotické ruce, které jsou uzpůsobené k péči, nebo výraz obličeje, který navozuje uklidnění či radost, a především stále přítomného lidského asistenta, kterého Eurobarometr 382 ve své studii zcela opomíjí.
Dotazník tak zcela nevhodně staví respondenta do pozice buď–anebo. Buď bude o mě nebo o mé blízké pečovat jenom lidský pečovatel, nebo jenom robot.
Tím vytváří falešné dilema a předkládá běžnému Evropanovi nutnost rozhodnout se mezi lidskou emotivní a empatickou péčí – a opuštěním svých blízkých, kteří budou následně předáni do péče studenému bezcitnému robotu. Důležitým krokem k nápravě této nešťastné situace, která nyní částečně svazuje ruce při přijímání důležitých politických rozhodnutí, je provést Eurobarometr (nebo obdobné šetření v rámci EU) znovu a propříště metodologicky správně.
Analýza skepse
Skepse velké části Evropanů ohledně využití robotů v sociálních službách nicméně nemusí zrcadlit jen jejich neinformovanost nebo nechuť k novým technologiím. Naopak může jít o explicitní vyjádření odůvodněného morálního odporu, který je intuitivně silně přítomen v širších vrstvách společnosti. Jenže i když veřejnost morální intuice v odpovědi na otázky Eurobarometru manifestuje, není v pozici explicitně vysvětlit, proč takové postoje přijímá. Není však úkolem každého dotazovaného přesně vědět, proč ten který názor zastává. To je spíše zadání filozofů a etiků, kteří vytvářejí argumenty, jež obhajují obecné morální postoje, a veřejnost se pak může k těmto argumentům přihlásit.
V relevantní literatuře najdeme hned několik skeptických argumentů ohledně využití robotů v sociálních službách. Kritici se často opírají o ústřední termíny etiky, jako jsou důstojnost, autonomie nebo důvěra. Pokud by se opravdu ukázalo, že využití robotů v obdobných profesích je v kolizi se základními etickými východisky naší společnosti, byl by to pro jejich širší nasazení obrovský problém.
Předně považujeme za důležité zdůraznit, že silná vyjádření odporu k nasazení sociálních nebo ošetřovatelských robotů nejsou v odborné literatuře příliš častá. Před dvaceti lety, na počátku robotické revoluce, se kritiky objevovaly opakovaně, avšak časem jejich frekvence opadla. Zřejmě to souvisí i se stále častějším nasazením robotů k různým úkolům a velice nízkou úrovní škod (i morálních), které jejich nasazení zapříčinilo. Nás však nebude zajímat aktuální frekvence problematických situací při práci robotů, ale filozofická relevance argumentů, které se proti jejich nasazení vymezují. Ne vždy byly adresovány jasně a často zůstávaly bez odpovědi. Cílem zbylé části reportu je argumenty skeptiků podrobně představit, upozornit na jejich slabá místa a ukázat, že i když je bereme vážně, pořád umožňují nasazení robotů ve vybraných, poměrně důležitých oblastech sociální starostlivosti. Což je, dle nás, důležité parciální vítězství pro zastánce pečovatelské robotiky.
Jedním z prvních ucelených textů v oblasti kritiky využití robotů v sociálních službách je stať autorů Sparrow a Sparrow (2006). Autorská dvojice je ve svých závěrech velice nekompromisní. Podle nich se užití robotů rovná podvodu:
…domníváme se, že pokusy nahradit skutečné sociální interakce robotickými simulakry jsou nejen pomýlené, ale ve skutečnosti neetické.
Co vede oba badatele k tak silnému prohlášení? Svou úvahu opírají o analýzu standardních sociálních interakcí. Aby spolu lidé či organismy mohli komunikovat, nebo jakýmkoliv jiným způsobem interagovat, musí splňovat jisté předpoklady. Komunikovat s druhým znamená mít s ním/ní opravdový vztah. Předpokladem oboustranného vztahu je existence potřeb či tužeb druhé strany. V sociálních službách máme na jedné straně klienty, kteří potřebují péči. U nich je tužba být opečováván evidentně přítomna. Jak je to na straně robotických pečovatelů? Jenom když i oni chtějí pomáhat, interagovat či komunikovat, mohou tak opravdu činit. Kdyby nechtěli pomáhat, a přesto nadále s klienty interagovali, jenom by pomoc předstírali, nebo rovnou o povaze své práce lhali. Intence a snažení je východiskem většiny našeho jednání. Jestli mají roboti s námi jako klienty smysluplně interagovat, musí jejich jednání vycházet ze stejných východisek. Jenže, říkají autoři, roboti ve skutečnosti nic nechtějí, nemají opravdové zájmy ani intence. Jenom konají. Jejich vztahy s lidmi tedy nejsou příkladem oboustranných vztahů, nemohou zakládat opravdovou komunikaci ani starostlivost. Navíc, jak tvrdí Sparrow a Sparrow, je existence autonomie rozhodování každého z nás konstituována i morálním uznáním ze strany druhého člověka:
… součástí rozhodování, které chápeme jako projev autonomie ze strany toho, kdo rozhodnutí činí, je přisouzení morální váhy jeho tužeb druhou osobou.
To znamená, že, pokud nepřisuzujeme druhému snahu dělat věci cíleným způsobem, nevidíme v něm morálního aktéra. Je zřejmé, že robotické systémy a automaty nemají schopnost druhému morální váhu přisoudit. Dělají, jako kdyby klientům pomáhali a komunikovali s nimi, ale je to jenom přetvářka. Protože nemají požadované tužby a intence, nejsou odpovídajících činností schopni. Pomoc jenom simulují, ve skutečnosti nepomáhají. Kromě toho nedisponují ani dalšími vlastnostmi, které by jejich péči kompletizovaly. Robotům chybí soucit a základní pochopení (psychické) zranitelnosti druhého:
Artefakty, které nechápou fakty o smrtelnosti a lidských zkušenostech, u nichž je přiměřené uronit slzu, nejsou schopny plně pečovat o druhé.
Jde o další důvod domnívat se, že robotické systémy se nehodí pro pečovatelskou práci. Pokud nechápete lidské bytosti v jejich komplexnosti, která zahrnuje i vědomí jejich smrtelnosti, nemůžete o ně adekvátně pečovat. Autoři Sparrow a Sparrow shrnují svoji silnou tezi tímto důležitým upozorněním:
… dle našeho názoru je jakékoli další omezování už i tak často minimálního lidského kontaktu [opečovávaných] neobhajitelné.
I když se dá s některými tezemi autorů souhlasit, v závěru našeho textu ukážeme, že mnohá jejich tvrzení jsou příliš silná a nekonstruktivní. Současně ukážeme, že limitované nasazení robotů v sociálních službách se ve skutečnosti dá dobře zdůvodnit.
Věnujme se ale ještě chvíli argumentům, které nasazení robotů v pečovatelství odmítají. Kritický pohled na robotizaci v této oblasti má i Sharkey (2014), který omezení lidského kontaktu poměřuje z hlediska opečovávaných lidí. Konstatuje, že kdyby se o starší lidi (nebo pacienty obecně) měli starat především roboti, a důsledkem této starostlivosti by bylo omezování mezilidských vztahů, mnoho takto zasažených by své životy považovalo za neodůvodněně ochuzené. Nejenom z hlediska vnějších pozorovatelů (jak to bylo v případě autorů Sparrow a Sparrow), ale i z pohledu dotčených osob se robotizace pečovatelství nejeví jako správné řešení. Stejný autor se (jako spoluautor) vyjádřil obdobně i ve starším textu (Sharkey a Sharkey 2011). Tam nastoluje odlišný argument proti uplatnění robotů, který jsme již v jiné podobě viděli u dvojice Sparrow a Sparrow. Týká se vnější podoby pečovatelských robotů. V odborných kruzích se bohatě diskutuje o vizuální podobě robotů, kteří se budou brzy pohybovat mezi námi. Existuje například zajímavá diskuze o fenoménu uncanny valley, kdy nastává neobvyklý jev vizuálního odporu k robotům, kteří jsou humanoidní, ale ne úplně dokonale. Sympatičtí jsou nám roboti, kteří vypadají hodně uměle, i ti, kteří jsou téměř neodlišitelní od lidí. Jakmile ale podobnost není příliš dobrá, stanou se pro nás roboti mimořádně nesympatičtí. (Víc o problematice Gray a Wegner 2012.) Sharkey a Sharkey upozorňují, že vizuální podoba robotů nevede jenom k náklonnosti či odporu. Robotičtí společníci pro staré lidi nebo robotické chůvy pro děti už i dnes jsou a pravděpodobně i v budoucnu budou navrženi tak, aby jejich vzhled, pohyby a interakce navozovaly u lidí tendenci připisovat jim mentální stavy. Z mnoha psychologických experimentů víme, jaké podmínky musí umělé (a je jedno, zda reálné nebo virtuální) systémy splňovat, aby byli lidé připraveni považovat je za potenciální nositele myšlenek, tužeb a emocí. Jenže samotná vizuální podoba robotů nic neříká o vnitřních mechanismech a skutečné povaze jejich rozhodovacích procesů. Je celkem dobře možné, že robot, který se člověku mimořádně podobá a kterého budeme spontánně považovat za myslící a emoční bytost, žádný psychologický život prostě nemá. Jde jenom o dobře naprogramovaný stroj, který nedisponuje myšlenkami, tužbami ani dalšími mentálními stavy. Naopak nevzhledná robotická krabice, o které bychom to nikdy neřekli, může při správném kopírování lidských psychologických stavů disponovat bohatým vnitřním životem. Na podobných úvahách je podstatné to, že nás opět vrací do debaty o podvodech, simulacích a etice užití robotů v interakci s lidmi. Vizuální podoba umělých pečovatelů navozuje u klientů, seniorů nebo dětí dojem, že roboti kolem nich jsou myslící a cítící aktéři, kterým hlavou probíhají obdobné procesy jako nám. Je ale morálně správné být takhle šizen? Autoři dávají opatrnější odpověď, než bychom ve světle již vyřčené dávky skepse očekávali. Jistá míra (nejen) vizuálního podvodu může být oprávněná. Když vnější podoba usnadní komunikaci s robotem, napomůže vytvoření důvěry a tím zlepší celkovou úroveň péče, může být legitimní, i když v nás vyvolává nesprávná psychologická a epistemická očekávání. Samozřejmě že nevinná iluze může přerůst ve vážnější problém. Klienti si mohou kvůli vizuální iluzi vytvořit k robotům specifické pouto, od kterého očekávají víc, než je robot schopen poskytnout. Takové přehnané očekávání potenciálně vede k psychickým a jiným problémům. Vždy je tedy potřeba zvažovat, zda případné ztráty, které mohou klienti nebo pacienti utrpět, nejsou vyšší než případné zisky. Sledujeme zde významný argumentační posun. I kdyby se ukázalo, že užití robotů se opírá o podvod nebo simulace, může být jejich nasazení v některých situacích legitimní. Není to tak, že by podvod byl předem morálně zavrženíhodný a neobhajitelný. Je důležité poměřovat výhody a nevýhody jednotlivých situací a konkrétních podob interakce mezi člověkem a robotem. Jako mnoho jiných problémů, i nasazení robotů v pečovatelství se ukazuje jako silně kontextuální. Vhodnost využití umělých ošetřovatelů závisí na mnoha dalších faktorech.
Co znamená jednat?
Právě existence mnoha vrstev opečovávání si detailně všímají autoři Santoni de Sio a van Wynsberghe (2016). Vycházejí z rozlišení, které je typické pro filozofii konání (philosophy of action). Obecně známe dva druhy činů: jedny jsou zaměřeny jenom na dosažení cíle, druhé mají vlastní vnitřní hodnotu starostlivosti a nazýváme je zkušenostní. První, na cíl zaměřené akty, směřují k naplnění svého poslání. Abychom použili příklad z medicínského prostředí: když přenáším pacienty z pokoje do ambulance, moje na cíl zaměřená akce je právě onen přenos. Činnost je úspěšná, když pacienta bez újmy přenesu na místo určení. Zdá se, že příznivci robotů by rádi poměřovali důvody jejich nasazení právě s ohledem na úspěch v činnostech, zaměřených na dosahování cíle. Je docela dobře možné, že roboty opravdu dokážeme sestrojit tak, aby bezproblémově přenášeli pacienty nebo klienty v rámci zdravotnických a ošetřovatelských zařízení z jednoho místa na druhé.
Jenže jak Santoni de Sio a van Wynsberghe upozorňují, lidské chování je obvykle mnohem bohatší. Autoři se opírají o centrální teze z etiky péče (Tronto 1993), které jako nepostradatelné části lidského chování k druhým zahrnují pozornost, odpovědnost, kompetenci ke konání a reciprocitu jednání. Takže i kdyby se mohlo zdát, že často konáme, jenom abychom dosáhli určitého cíle, ve skutečnosti děláme mnohem víc. Když sestra přenáší pacienta z pokoje do ambulance, ptá se ho, jak se má, dohlíží na jeho pohodlí, věnuje pozornost případným změnám chování nebo zdravotního stavu. Jinak řečeno, přenáší jej a současně o něj všestranně pečuje. Jak ukazují autoři na jiném příkladu:
Abychom správně vykonali činnost zvedání, nestačí, aby ošetřovatel jenom efektivně a bezpečně přesunul pacienta z jednoho místa na druhé, ale aby si také pěstoval pozorovací schopnosti a naplňoval veškeré důležité sociální a zdravotní potřeby pacienta.
Jde o příklad zkušenostního jednání: nehledíme na cíl, ale zajímají nás zkušenosti druhých, aktivně o ně pečujeme a tahle péče nás samotné naplňuje. Samozřejmě že ani u zkušenostního jednání se cíl akce neztrácí. Pořád chceme pacienta komfortně dopravit z pokoje do ambulance. Avšak nezůstáváme jenom u úzce vymezeného cíle, ale s pacienty aktivně komunikujeme, uklidňujeme je, sledujeme ukazatele zdraví a dohlížíme na jejich obecné pohodlí. Tohle všechno každý z nás nesčetněkrát zažil, ale i tak je potřeba komplexnost situace detailně vnímat a reflektovat. Jestli mají roboti v pečovatelství nahradit lidské bytosti, je namístě od nich vyžadovat stejný, ne-li vyšší standard, jaký běžně zabezpečují dosavadní lidští ošetřovatelé a ošetřovatelky. S ohledem na aktuální rozvoj robotiky a předpokládaný technický pokrok se nezdá, že by roboti byli v dohledné době schopni detailní zkušenostní péče, na jakou jsme zvyklí.
Komplikace a řešení
Situace je ale zas o něco komplikovanější, než z uvedeného plynulo. Využití zkušenostních postupů je celkem jistě v mnoha pečovatelských situacích žádoucí, ale není potřebné pokaždé. Někdy opravdu stačí jenom přenést klienta z jedné místnosti do druhé a nic jiného nás nezajímá. Pokud platí, že přenos s ohledem na konkrétní cíl zvládnou i umělé systémy, opět jsme při kontextovém určení naznačili situace, ve kterých je jejich nasazení možné. Využitelnost robotů se odvíjí od konkrétních potřeb opečovávaných lidí v každém daném okamžiku. S tím souhlasí i citovaní autoři, když způsob starostlivosti přizpůsobují požadavkům zaopatřovaných klientů:
Raději bychom rozhodnutí o tom, jak je potřebné se o ně starat, nechali na samotných starších lidech.
Zatím jsme viděli dva různé postoje k využití robotů v sociálních službách. První je nekompromisně kritický a zdůrazňuje zásadní pokles kvality a úplné selhání péče při nasazení robotických systémů. Z morálního hlediska pak musíme robotizaci pečovatelských služeb jednoznačně odmítnout. Druhý postoj je méně vyhraněný a upozorňuje, že v jistých situacích bychom si pomoc robotů dokázali představit. Problém prvního přístupu spočívá v odmítaní jakýchkoli změn, i kdyby byly dobře připraveny. Nepřipouští ani teoretickou možnost, že by nasazení robotů mohlo vylepšit složitou situaci v sociálních službách, které jsou trvale podfinancované, na zaměstnanecké úrovni genderově velice nevyvážené a pro klienty často mimořádně obtížně dostupné. Ani druhý přístup není bez problémů. I když připouští existenci případů, ve kterých by pečovatelští roboti mohli být nápomocni, nespecifikuje dostatečně podmínky, za jakých taková situace může nastat. Nestačí jenom říct, že zřejmě existují kontexty, ve kterých budou roboti vhodní. Je potřeba takové kontexty dále upřesnit a neodkazovat se jenom na jakési imaginární zvažování pro a proti jejich nasazení nebo na blíže neurčený názor dotčené klientely.
Proto chceme v závěru textu představit scénář, který nastíní, za jakých podmínek se nám jeví využití robotů v sociálních službách jako odůvodněné. Nepůjde nám o sci-fi scénář jakési nesmírně vzdálené budoucnosti, budeme vycházet z podmínek celkem dohledné doby. Nejprve se však musíme blíže podívat na samotný pojem robota.
Ve všech výše citovaných textech (a bezpočtu dalších, které se tématu věnují) se termín robot používá, jako by bylo jasné, o čem mluvíme. Jenže když se podíváme i na dnešní, celkem nedokonalé roboty, zjistíte, že existuje mnoho tříd těchto strojů. Výrazně se od sebe liší industriální svářecí roboti, robotický vysavač, robotický pes nebo konverzační robot. Každý z nich vyniká v jiné oblasti a obvykle je připraven čelit vybraným úkolům, přičemž na cokoliv dalšího jeho schopnosti nepostačují. Pro potřeby pečovatelství je namístě rozdělit si roboty na několik podkategorií, zejména s ohledem na jejich schopnosti (naší inspirací byl text Caic, Odekerken-Schroder a Mahr 2018). Nejjednodušší jsou čistě asistenční roboti, již fyzicky pomáhají při nejrůznějších úkolech. V nemocnicích a domovech zvedají pacienty, přinášejí či aplikují léky, převážejí nebezpečný materiál. Nedisponují žádnými kognitivními schopnostmi, maximálně se orientují v prostoru, dovedou najít cíl své cesty a vyhýbají se překážkám. Další skupinou jsou konverzační roboti. Jejich fyzické schopnosti nejsou důležité, mají za úkol zejména komunikovat s pacienty, bavit je, ptát se na zdravotní stav a naplňovat jejich sociální potřeby. Slouží i personálu, protože jej mohou informovat o zdravotních změnách, které detekovali u pacientů, a pomáhají předcházet vysilujícím sociálním interakcím ze strany pečovatelů. Ještě sofistikovanější jsou emoční roboti. Nejenom že dokážou plynule konverzovat, ale chápou emoce opečovávaných i zaměstnanců, vyjadřují soucit i radost a dokážou adekvátně a citlivě reagovat. Témata diskuzí mění na základě analýzy nálad svých konverzačních partnerů, navrhují debaty o oblastech, které opečovávané baví, a vyhýbají se těm kontroverzním. Nejdokonalejší roboti, někdy nazývaní androidi, disponují všemi vlastnostmi, které očekáváme od člověka, přičemž některé z limitů lidských vlastností (jak po fyzické, tak i psychické stránce) mohou svými schopnostmi významně překonávat. Dovedou všechno, co se od nich očekává, a naplňují požadavky zkušenostního jednání. Označíme je jako sociálně-emoční, protože kromě všech psychologických vlastností a fyzické zdatnosti chápou složitost lidské sociální situace, citlivě vnímají potřeby klientů, umějí jednat s jejich rodinnými příslušníky, chápou společenské konvence i tabu, rozumějí medicínským potřebám apod. Androidi by byli ideálními pečovateli. Jenže jimi nejsou (a dlouho nebudou), protože nevíme, jak je navrhovat a stavět. Prozatím máme obrovský problém vyrábět spolehlivé roboty, od kterých požadujeme více než několik málo monotónních úkolů. Při troše zjednodušení můžeme říct, že jakž takž zvládáme budovat a zavádět do pracovního procesu asistenční roboty, máme částečné úspěchy s konverzačními roboty, ale o moc dál jsme se nedostali. Jak kombinovat emoce a sociální dovednosti se zbylými psychologickými schopnostmi a fyzickými dovednostmi zatím vůbec netušíme a celkem jistě je představa dokonalého androida jenom divokou fantazií z filmů a komiksů, jejíž realizace je v nedohlednu.
Triviální pravdou je konstatování, že čím složitější technologii chceme sestrojit, tím déle nám to potrvá. Asistenční roboti jsou již tady, konverzační už téměř taky. Emoční tu budou zřejmě někdy ve střednědobém horizontu a androidi možná někdy v budoucnu. Znamená to tedy, že když jsou androidi jedinými vhodnými celostními pečovateli a jejich budoucnost je nejasná, máme se prozatím vzdát jakýchkoli úvah o nasazení robotů v sociálních službách? Ne tak docela.
Podívejme se na proces z druhé strany, z pohledu opečovávaných klientů a jejich nároků. Jak jsme již ukázali výše, nejrůznější druhy sociálních interakcí vyžadují skutečné tužby a záměry participantů u obou komunikujících a interagujících stran. Jenže doposud jsme mluvili jenom o robotech a shodli jsme se, že u nich požadované psychologické stavy nenacházíme. Co když ale někdy absentují i u lidí? Nemyslíme teď na komplikované filozofické diskuze o eliminativismu ohledně mentálních stavů nebo na různé psychologické obhajoby behaviorismu, které všechny říkají, že ve skutečnosti nikdo z nás doopravdy mentální stavy nemá. Takové názory považujeme za extrémní a tudíž ne příliš zajímavé. Soustředíme se na méně kontroverzní scénáře lidských subjektů, u kterých je absence záměrů a tužeb vysoce pravděpodobná a rozpoznání této absence je pro mnohé z nás přijatelným zjištěním.
Existuje několik skupin pacientů, kteří jsou z důvodu věku nebo nemoci natolik mentálně indisponováni, že není jasné, zda lze vůbec jejich psychologické stavy srovnat s našimi a zda jejich vnitřní život zahrnuje opravdové mentální stavy jako tužby nebo emoce. Mluvíme o pacientech v dlouhodobém vegetativním stavu, s těžkou demencí nebo pokročilou Alzheimerovou nemocí. V uvedených případech (a zřejmě i dalších) je absence psychologického života zřejmá jak pro nezainteresovaného pozorovatele, tak i pro erudované badatele.
Není náhodou, že pacienti s obdobnými diagnózami patří z pohledu péče a starostlivosti mezi ty nejtěžší. Práce o ně může být frustrující a lehce vede u pečovatelů k syndromu vyhoření právě proto, že takoví klienti nejsou schopni vyjádřit vděk, sympatii ani jinou pozitivní či negativní emoci. Pečovatelé nemají zpětnou vazbu na svoji práci a absence emocí u ošetřovaných jim neumožňuje využít zkušenostní postupy, o kterých jsme mluvili výše. Důležité je taky si uvědomit, že reciprocita vztahu porozumění, která je pro péči ústřední, zde neplatí. Pacienti ve velice těžkém rozpoložení nejsou ve stavu, aby od druhých očekávali potřebu starat se o ně, nebo předpokládali u nich související tužby a přesvědčení, o které se starostlivost opírá. Jejich svět již neobsahuje příslušné kognitivní a metakognitivní postupy, díky kterým by na druhé projektovali požadované psychologické stavy. Takhle postižení pacienti se nesituují ke svým pečovatelům z východiskové pozice, kterou očekáváme u běžné populace. Na péči o ně pozorujeme asymetrii vztahu, ve kterém pečovatelé (obvykle) postupují zkušenostně, ale pacienti recipročního vztahu nejsou schopni.
Protože k uvedené asymetrii téměř jistě dochází, padá předpoklad, ze kterého vycházeli kritikové nasazení robotů, citovaní výše. Když pacienti nejsou ve stavu požadovat zkušenostní zacházení, možná není nutné jim ho, alespoň v některých kontextech, poskytovat. Zde se otevírá nový prostor pro nasazení asistenčních robotů. Bylo by skvělé, kdyby byli schopni zkušenostního jednání, ale není to vždy nutné. Pro běžné a rutinní úkony, jako jsou přenosy, převozy, zvedání, distribuce léků nebo kontrola proleženin, by se mohla uplatnit robotická síla, které nepřekáží asymetrie interakcí, jež může být pociťována lidským personálem. Samozřejmě, pro jiné úkony by byly pořád potřební standardní lidští pečovatelé – ať už jde o medicínské vyšetření, nebo psychologické testování. Stále je zde ale dost činností, které by mohli na pacientech vykonávat roboti. Je důležité, že v těchto případech nenarušujeme symetrii psychologických předpokladů spolupráce a péče. Nejde tedy o podvod, protože klienti neočekávají ekvivalent lidského zkušenostního zacházení. Ve výsledku by nasazení robotických asistentů za uvedených podmínek bylo morálně akceptovatelné.
Závěr
Představili jsme několik argumentů, které měly ukázat, že nasazení robotů v pečovatelských službách je morálně diskutabilní, nebo přímo neakceptovatelné. Argumentace se opírala o detailní filozofickou analýzu předpokladů jednání. Analýza správně poukazovala na to, že předpokladem cílevědomého lidského jednání je přítomnost složité sítě psychologických stavů, z nichž jsou mnohé reciproční nebo metakognitivní. Argumentace odpůrců využití robotů se pak soustředí na fakt, že umělé systémy takovou sítí nedisponují a jejich údajné dovednosti jsou tedy nemorálním podvodem. Z uvedeného důvodu chápou případné nasazení robotů ve zdravotnictví a ošetřovatelství jako vysoce neetické.
My jsme se v textu snažili optiku pootočit a ukázat, že v případě mnoha na péči extrémně náročných pacientů může být asymetrie očekávání zkušenostního jednání narušena. Takhle postižení pacienti nejsou ve stavu, kdy by očekávali od druhých plnohodnotné, psychologicky fundované zacházení. Proto robotická asistence u mnoha činností, spjatých s péči o ně, nemůže být chápána jako neetický podvod. Naopak může pomoct zlepšit systém, který je chronicky podfinancovaný, obecně nedoceněný a v případě nejtěžších pacientů, o kterých je zde řeč, i psychologicky a fyzicky nesmírně náročný pro všechny jejich lidské ošetřovatele.
Literatura
Caic, M., Odekerken-Schroder, G., a Mahr, D. Service robots: value co-creation and deconstruction in elderly care networks. Journal of Service Management, 2018, roč. 29, č. 2, s. 178–205.
Gray, K., Wegner, D. M. Feeling robots and human zombies: Mind perception and the uncanny valley. Cognition, 2012, roč. 125, č. 1, s. 125–130.
Santoni de Sio, F., van Wynsberghe, A. When should we use care robots? The Nature-of-Activities Approach. Science and Engineering Ethics, 2016, roč. 22, č. 6, s. 1745–1760.
Sharkey, A. Robots and human dignity: a consideration of the effects of robot care on the dignity of older people. Ethics and Information Technology, 2014, roč. 16, s. 63–75.
Sharkey, A., Sharkey, N. Children, the Elderly, and Interactive Robots. IEEE Robotics & Automation Magazine, 2011, roč. 18, č. 1, s. 32–38.
Sparrow, R., Sparrow, L. In the hands of machines? The future of aged care. Minds and Machines, 2006, roč. 16, s. 141–161.
Tronto, J. Moral boundaries: A political argument for an ethics of care. New York: Routledge, 1993.
Report je ke stažení zde.



Governance and Ethics of AI: Status and Current Global Challenges
Přednáška
Centrum pro environmentální a technologickou etiku – Praha (CETE-P) ve spolupráci s Karlem Čapkem Centrem pro hodnoty ve vědě a technice (CEVAST) pořádá přednášku prof. Christopha Lütge, ředitele Institutu pro etiku AI při mnichovské Technické univerzitě (TUM). Prof. Lütge je vlivný odborník na etiku nových technologií a byznys etiku. Téměř od počátku existence CEVAST je také jeho externím členem.
Všichni jsou srdečně zvání na Christophovu přednášku. Přednáška a diskuse proběhne v angličtině bez překladu.
Cookies
