
Umělá inteligence jako zdviž do naší budoucnosti
Jiří Wiedermann, Jan van Leeuwen
zde.Co to je: je to moudré, ale není to živé? Přesně taková entita se v poslední době objevila mezi námi. Nikdo neví, jak vypadá, jestli má tělo, nějaké smysly, je inteligentní. Jediné, co víme, je, že údajně sídlí na „výpočetním oblaku“. Ale všem, kteří se s ní stýkali anebo aspoň o ní slyšeli, je zcela jasné, že se s ní dá dorozumět mnoha jazyky, lze s ní rozumně konverzovat v podstatě na jakékoliv téma, v drtivé většině konverzaci dobře rozumí, smysluplně argumentuje, ale bohužel si občas vymýšlí a lže. Samozřejmě, řeč je o generativní umělé inteligenci. Její vlastnosti jsou tak zajímavé a rozporuplné, že debata o ní přitáhla pozornost laické i odborné veřejnosti a ovládla velkou část mediálního prostoru. Odborníci z oblasti umělé inteligence, neurovědci, filozofové, kognitivní vědci, jazykovědci, význačné osobnosti byznysu, a intelektuálové se přou, jestli není nebezpečná pro lidstvo, jak moc je užitečná, jestli má nějaké mentální vlastnosti srovnatelné s lidskými, a jestli vůbec, či za jakých podmínek, ji dále rozvíjet. Máme se s ní bratříčkovat, obejmout ji, kultivovat, rozvíjet ji, spolupracovat s ní, anebo naopak, stranit se jí, zakazovat ji, bát se ji a nepokoušet se ji zvelebovat?
Pokud tedy odborná i laická veřejnost pochybuje o tom, jestli jsou pro nás zatím tušené možnosti umělé inteligence potenciálně nebezpečné, má jistě smysl ptát se,
„Proč vlastně rozvíjíme umělou inteligenci?“, resp.
„Jaký účel má používání umělé inteligence?“
Odpovědi na takové otázky jsou jednoduché, pokud se ptáme na konkrétní vývoj a smysl systémů umělé inteligence, které řeší nějaké konkrétní a známé problémy. Pokud se ale jedná o umělou inteligenci, které bude obecná v tom smyslu, že dovede řešit jakýkoliv problém a dělat vlastní rozhodnutí, je odpověď složitější. V tomto případě nás zajímají odpovědi na naše dvě otázky, vycházející z hlubšího pochopení pojmu umělé inteligence a jejího dosavadního vývoje. Tyto by měly vyplývat z nějakého konceptu, jež platí pro „jakoukoli umělou inteligenci“, přinesou nové vhledy do povahy umělé inteligence a dovolí extrapolaci trendů v oblasti umělé inteligence, a tím pádem umožní racionální představy o budoucnosti umělé inteligence. Pod pojmem „jakákoliv umělá inteligence“ rozumíme jak to, co v současné době považujeme za umělou inteligenci, tak i veškeré druhy uměle vytvořené inteligence v budoucnosti, jak na Zemi, tak kdekoliv ve Vesmíru.
Chceme, aby nám naše odpovědi na výše uvedené odpovědi umožnily zjistit, kam se bude umělá inteligence ubírat. Jak ale můžeme určit, kam umělá inteligence směřuje? Můžeme identifikovat žádoucí směr dalšího vývoje, který je podložen důkazy? Jaké důsledky bude mít pro naši budoucnost? Existují nějaké překážky, kterým se musíme vyhnout?
Přesvědčivé argumenty k zodpovězení takových „dílčích otázek“ lze uvést pouze tehdy, jsou-li podloženy nepřehlédnutelnými fakty. Proto se naše argumentační linie budou opírat o historické a současné trendy v informačních technologiích, konkrétně v umělé inteligenci, a také o filozofické úvahy a částečně o formální teorii. To nám pomůže vysledovat objektivní povahu problému a v tomto rámci navrhnout nejen dobře podložené odpovědi, ale také extrapolaci významu rozvoje umělé inteligence pro naši budoucnost.
Ukážeme, že budoucí umělá inteligence se bude kvalitativně lišit od té současné tím, že bude využívat znalosti a zkušenosti k účelnému jednání. To propůjčí systémům umělé inteligence novou pokročilou schopnost, kterou lze shrnout pod pojem umělé moudrosti. V kontextu systémů AI je umělá moudrost novým pojmem, který zvýší schopnost budoucích systémů vyrovnat se se složitostí, proměnlivostí a nejednoznačností reálného světa, které tradiční systémy nebyly schopny. Příslušné systémy budou mít schopnost učit se v průběhu času, přizpůsobovat se, řešit složité problémy a samostatně se rozhodovat. V neposlední řadě budou schopny činit etická rozhodnutí.
Z toho dále odvodíme vizi budoucí umělé inteligence, která se řídí umělou moudrostí a která je přitažlivá, věrohodná a bezpečná. Vysvětlíme, proč a jak lze takovou AI považovat za výtah do naší budoucnosti a za jakých okolností se jí nebudeme muset bát.
Trendy ve využívání výpočetních technologií
Pro identifikaci trendů v oblasti umělé inteligence budeme vycházet z trendů rozvoje výpočetních technologií od jejich počátků zhruba v polovině 20. století až po současnost. Přehledně jej zachycuje obr. 1. Zde vidíme, jak výpočetní síla počítačů průběžně exponenciálně rostla v souladu s Mooreovým zákonem a jak se měnily odpovídající výpočetní prostředky a paradigmata.
Z hlediska této kapitoly je však zajímavější pohled na předchozí výpočetní technologie zachycující proměnu typu zpracovávaných dat, a jejich způsobu zpracování, v závislosti
na nárůstu výpočetní síly, zachycený na obr. 2. Z obou obrázků je jasně vidět, jak s rozvojem informačních technologií a jejich aplikací rostla (a roste) jejich informační síla v rámci tzv. DIKW hierarchie: data, informace, znalosti, moudrost. Tato hierarchie zachycuje skutečnost, že v typickém případě je informace definovaná pomocí dat, znalosti pomocí informací, a moudrost pomocí znalostí.
Pojem DIKW hierarchie popularizoval v r. 1988 Russell Ackoff ve své prezidentské přímluvě k Mezinárodní společnosti pro systémové vědy. Nicméně, tato myšlenka se v různých podobách objevovala již dříve mezi odborníky zabývajícími se počítači, řízením a operačním výzkumem, a proto ji lze považovat za „lidovou moudrost“. Tato hierarchie se často zobrazuje jako pyramida postavená na datech a s moudrostí
ve vrcholu. Tvar pyramidy zachycuje fakt, že moudrost je nejvyšší formou znalostí, které je možné dosáhnout pouze na základě dat, které se transformují postupně přes informace a znalosti až na moudrost. To je znázorněno na obr. 3.
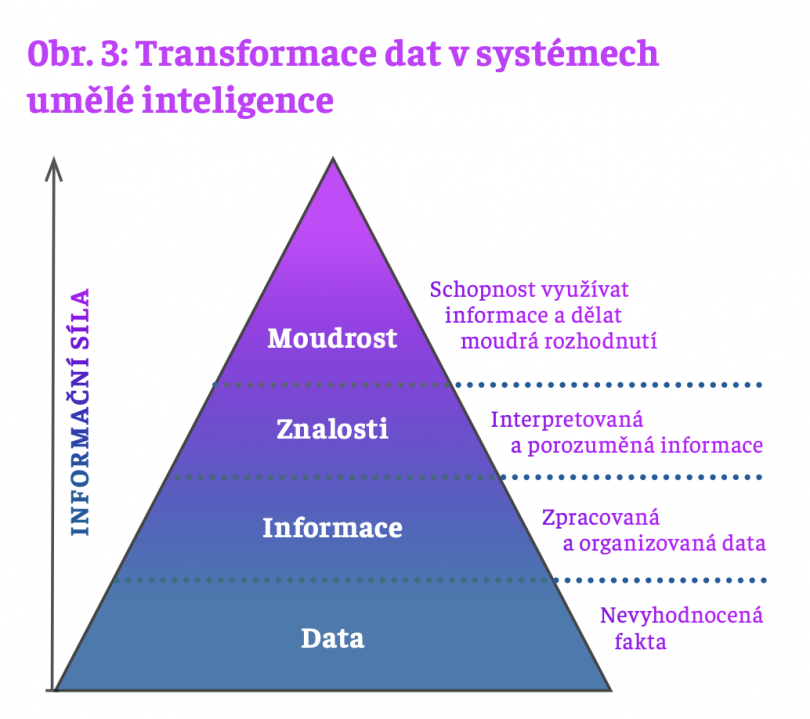
Není to vlastně nic jiného než hrubý nárys architektury systému pro zpracování dat. V jednotlivých obdélnících přilehlých k pyramidě je naznačeno, co je předmětem zpracování dat, ve směru zdola nahoru, na dané úrovni. Transformace dat mezi jednotlivými úrovněmi pyramidy se děje pomocí algoritmů, často velmi složitých (např. neuronové sítě, statistické výpočty, rozeznávání vzorů, identifikace trendů atp.), které závisí na požadovaném výsledku transformace a druhu dat vstupujícím a vystupujícím z procesu transformace. Přesněji, data vstupující do pyramidy mohou být čísla, texty, kódy, obrázky, výstupy různých senzorů, či jiná nevyhodnocená fakta. Zpracování na informační úrovni může zahrnovat statistické výpočty, rozeznávání vzorů, trendů apod. Ještě na vyšší úrovni znalostí jde o budování konceptů, odhalování zákonitostí a nacházení vztahů mezi různými skupinami informací. Konečně na úrovni moudrosti se hledají možnosti cílevědomé aplikace znalostí na nové situace. Zde přicházejí k slovu např. neuronové sítě imitující naše představy o práci mozku.
Kvalitativní rozdíl mezi daty na dvou přilehlých úrovních představuje míru porozumění datům na nižší úrovni, vyjádřené prostředky vyšší úrovně, vždy vzhledem k poslání příslušného systému. Je zřejmé, že taková míra porozumění roste ve směru zdola nahoru.
Uvedené schéma je velmi obecné, platí pro jakýkoliv systém umělé nebo přirozené inteligence, jenž generuje moudrost, bez ohledu na to, v jakém prostředí pracuje a jaké je jeho poslání. Platí to třeba pro automatické dveře, samo-řiditelné auto, autonomní systém řízení protiraketové obrany, pro systémy generativní umělé inteligence, pro mozek, dokonce i pro tzv. „superinteligenci“. Na této úrovni abstrakce je schéma práce takových systému stejná.
Podle Ackoffa, první tři úrovně hierarchie lze „programovat“ a tudíž automatizovat, kdežto poslední, čtvrtou úroveň, nikoliv, protože moudrost obsahuje i etické a morální aspekty, které nelze svázat žádnými jednotnými pravidly, protože závisí na rozhodnutích zájmových stran, které ovlivňují a realizují proces transformace dat, ale nikoliv produkt.
„…usuzuji, že člověk nikdy nebude moci svěřit automatům úlohu systémů generujících moudrost. Může se klidně stát, že moudrost, která je nezbytná pro účinné hledáni ideálů, a samotné jejich dosahování, jsou vlastnosti, které odlišují člověka od strojů.“
Pravdivost tohoto tvrzení velmi závisí na tom, co v kontextu umělé inteligence budeme považovat za moudrost. Existuje rozumná definice moudrosti, která se bude dát realizovat výpočetně, a tedy, svěřit strojům? Jak se díváme na Ackoffovo tvrzení ve světle současných trendů v rozvoji umělé inteligence? To uvidíme v dalších částech.
Od dat k moudrosti
V dalším budeme uvažovat systémy umělé inteligence ve formě vtělených kognitivních agentů. Jsou to fyzické entity, které mohou nepřetržitě vnímat své okolí, učit se ze své zkušenosti, předvídat běh událostí, jednat účelně a eticky pro splnění svých cílů a přizpůsobovat se měnícím okolnostem.
Pokud chceme porozumět práci konkrétního agenta, tak nás zajímá, s jakými daty a informacemi agent pracuje, jaké znalosti využívá, a na co je určeno „moudro“, které generuje. Pro tento účel se ukazuje jako vhodné dívat se na schéma z obr. 3 z perspektivy tzv. znalostní teorie výpočtů, vyvinuté před několika lety autory této práce. Tento pohled má tu výhodu, že přímo pracuje s pojmy užívanými v definici DKIW pyramidy, a tak jak postupuje transformace dat v této pyramidě, tyto pojmy vlastně výpočetně definuje. Z hlediska této teorie nahlížíme totiž na výpočty jako na výpočetní procesy, které generují znalosti a moudrost z informací nad danou znalostní doménou D pomocí dané znalostní teorie T.
Znalostní doména je souhrn informací o objektech, faktech, procesech reálného světa, které jsou předmětem zájmu agenta. Prvky znalostní domény tvoří podmnožinu reálného světa. Informace ze znalostní domény jsou systému dodány z části zvenčí a zčásti je získává ze svých vstupních dat, které načítají příslušné senzory. Načtením dat daným senzorem se data stávají informacemi takového typu, pro jaký je senzor určen. Tento typ dat musí souhlasit s typem informací, které tvoří znalostní doménu.
Výpočet dále pracuje tak, že kombinuje prvky znalostní domény – jimiž jsou již zmíněná informace (resp. jejich reprezentace), nazývané také elementární znalosti do odvozených, často složitějších konstrukcí, které již tvoří novou znalost, opět nad danou doménou a v rámci teorie T. Tato fáze zpracování odpovídá třetí úrovni DIKW pyramidy.
Pro kombinaci prvků této úrovně používá výpočet množinu (odvozovacích) pravidel, která může být předem daná v rámci teorie T, anebo se může tvořit pomocí učení během velkého počtu různých výpočtů nad danou doménou.
Systém tímto způsobem pracuje s více či méně formální teorii T, která zachycuje vlastnosti dané znalostní domény a způsoby odvozování nových znalostí, stále v rámci dané domény. Jakmile tedy systém načte nějaká data, tyto se stávají v rámci teorie T informací. Z nich systém shora popsaným způsobem generuje znalosti; některé z nich se jsou dále využívány na čtvrté úrovni pyramidy v rámci systému generování moudrého jednání (viz dále). Na této úrovni totiž vstupuje do hry, kromě transformace dat, další schopnost systémů umělé inteligence – a tím je jednání. V tomto smyslu je jednání cílená činnost systému směřující k naplnění jeho cílů, resp. poslání, pro které je systém zkonstruován, anebo se evolučně vyvinul.
Z hlediska znalostní teorie výpočtu považujeme za okolí systému (či agenta) tu část světa, kterou popisuje znalostní doména D. Řídícím systémem agenta je znalostní teorie T. Jaké jednání je považováno za účelné je definováno ve specifikaci poslání agenta. Specifikace poslání pro každou situaci určuje, jakou podmínku musí chování agenta dodržet, v závislosti na historii jeho předchozího jednání.
Proto je důležité si uvědomit, že specifikace poslání se nerovnají funkční specifikaci systému. Ty první určují, co má systém dělat, kdežto ty druhé, jak to má dělat.
Někteří agenti mohou mít speciální schopnost pro svoji činnost generovat a využívat speciální druh znalostí – (umělou) moudrost (Wiedermann & van Leeuwen, 2023). Moudrost se projevuje v jednání (chování) agentů, které za každých okolností naplňuje poslání systému.
Umělá moudrost agenta je jeho schopnost aplikovat své znalosti na jednání směřující za každých okolností k cílevědomému vytváření pragmatických hodnot, které je předepsáno v jeho specifikaci poslání, za současného dodržování etických hodnot.
Teď je jasné, proč se znalosti a moudrost nenacházejí na stejné úrovni v rámci DIKW hierarchie. Je tomu tak proto, že znalost je z pohledu znalostní teorie výpočtů výsledkem transformace dat a informací, tj. v podstatě je výsledkem jakéhokoliv výpočtu. Naproti tomu moudrost přináší do výpočtů specifickou formu zpracování znalostí nepřetržité cílevědomé a efektivní jednání (angl. agency) prostřednictvím synergetického efektu znalostí, kognice a jednání. Znalosti jako takové, samotné, představují pasivní formu znalostí, kdežto moudrost představuje jejich akční formu. Moudrost bez znalostí nemůže existovat.
Schopnost generovat umělou moudrost posouvá možnosti systémů umělé inteligence na kvalitativně vyšší úroveň v porovnání se systémy, které takovou schopnost nemají.
Tato schopnost agenta musí být popsaná v jeho znalostní teorii. Etika, resp. etické jednání může být popsané jako součást znalostní teorie anebo jako samostatná znalostní teorie. Moudrý agent tedy zaručeně za každých okolností vytváří pragmatické i etické hodnoty, specifikované v jeho poslání.
Formálně definovaná umělá moudrost umožňuje hovořit o moudrosti extrémně jednoduchých kognitivních systémů, jakým jsou např. automatické otvírané dveře. Jsou moudré, protože jednají tím způsobem, že otevřou dveře (vykonáním akce vytvoří pragmatickou hodnotu pro procházející osobu), kdykoliv rozeznají takovou potřebu (kognitivní schopnost), a chovají se eticky (pokud jsou zkonstruovány tak, že nikoho nepřivřou, a nic jiné se od nich nepožaduje. Složitější systém, jako třeba autonomní vozidlo, je také moudrý, protože (a pokud) pomocí kombinovaného efektu využití svých senzorů a motorů vytvoří pragmatickou a etickou hodnotu – doveze svého uživatele bezpečně k cíli.
V definici hierarchie DIKW se moudrost nachází v jejím vrcholu, což naznačuje, že nějaká „vyšší forma“ vědění neexistuje. Dokonce i tzv. „superinteligence“ je forma moudrosti. Moudrost se tak jeví jako ultimativní cíl umělé inteligence. Zde je na místě poznamenat, že takový cíl nelze dosáhnout v konečném čase. To dokazuje např. matematika, ve které existují nekonečné hierarchie různých znalostních teorií.
Definice umělé moudrosti je tedy ukotvená ve znalostní teorii výpočtů. To má důležité důsledek pro naše úvahy ze sekce 2, kde jsme korelovali pozorovaný nárůst „informační síly“ jednak jako vývojový trend v oblasti výpočetní technologie, a také jako proces charakterizující čtyři úrovně DIKW pyramidy (data, informace, znalosti, moudrost). Teď jsme ukázali, že všechny tyto úrovně jsou dosažitelná pomocí výpočtů.
Tento postřeh má dalekosáhlé důsledky. V následující části se podíváme na systémy umělé inteligence s potenciálem generovat umělou moudrost.
Velké jazykové modely: inteligence bez kognice
Existují již v současné době systémy umělé inteligence, které generují umělou modrost? Zatím ne, ale jistou představu o tom, jak by mohly systémy generující moudrost v budoucnosti vypadat, nám dávají současné velké jazykové modely jakými jsou model GPT fy OpenAI, PaLM modely fy Google, LLaMa modely fy Meta, apod. Tyto modely jsou součástí tzv. generativní umělé inteligence, která se učí vzory a struktury z příkladů, jak byla používaná minulá data. Tyto znalosti pak využívá pro interaktivní generování nových obsahů podobné kvality, jakou měly učící data, za účelem asistování uživatelům v jejich činnostech.
Z formálního hlediska, znalostní doménou velkých jazykových modelů je přirozený jazyk (či jazyky), znalostní teorie systému je implicitní model světa, popsaný v daném jazyce, jenž si systém buduje během své učící fáze, a etická teorie je libovolná znalostní teorie, která definuje jednání kompatibilní s představami strůjců systému.
Ukážeme, že tyto modely mají potenciál generovat umělou moudrost (Wiedermann & van Leeuwen, 2023). Toto tvrdíme i přesto, že je známé, že tyto modely jsou velmi křehké (náchylné ke katastrofickým selháním), nespolehlivé (schopné dodat nesprávnou anebo vymyšlenou informaci), příležitostně schopné dělat elementární logické chyby v uvažování anebo v jednoduchých počtech. Náš argument ve prospěch tohoto tvrzení vychází z paradigmatu málo užívaného v oblasti umělé inteligence, kybernetiky anebo robotiky, ale o to známějšího v kognitivních vědách: paradigma 4E kognice (Newen, De Bruin, Gallagher, 2018). Toto paradigma postuluje, že kognice není pouhým vnitřním, individuálním procesem, nýbrž se jedná o emergentní proces, jež vzniká interakcí mezi mozkem, tělem, okolím a sociálním kontextem. Zkratka 4E pochází z angličtiny a naznačuje, že kognice je vtělená, vnořená, vykonávaná, a rozšířená (embodied, embedded, enacted, extended) pomocí mimo-mozkových procesů a struktur.
Vtělenost znamená, že kognice je ukotvená v našich smyslech, tělech a fyzikální zkušenosti. Vnořenost hovoří o tom, že kognice je součástí našeho způsobu života. Vykonatelnost konstatuje, že kognice slouží cílevědomé akci v reálném světě. A konečně rozšířenost vidí kognitivní systém jako celek zahrnující i prostředí včetně dalších lidí, nástrojů a zařízení.
Zastánci 4E kognice argumentují, že shora uvedené čtyři atributy mají vztah k inteligenci systémů, které splnění příslušných atributů vykazují. Atributy 4E kognice nelze přímo aplikovat na velké jazykové systémy, už jenom proto, že tyto nemají tělo, smysly, anebo efektory. Nicméně, ve všech čtyřech případech atributů 4E kognice můžeme v kontextu takových systémů hovořit o nepřímé vtělenosti, nepřímé vnořenosti, nepřímé vykonatelnosti, a nepřímé rozšířenosti. Vlastnost „nepřímosti“ pramení z toho, že velké jazykové modely nemají kognitivní aparát, který by jim umožnil přímou interakci s prostředím. Jak jsme však zmínili výše, jejich znalostní teorie obsahuje implicitní model světa, který si systém extrahoval z popisů světa a jeho vlastností jakoby „z druhé ruky“, zprostředkovanými lidmi v písemných podkladech, ze kterých se model učil. Všimněme si, že v takovém případě jazykové modely nevnímají svět „tak, jak vypadá“, tj. tak, jako ho vnímáme my lidé, ale pouze (neboli přesně) tak, jak se o něm, včetně o umělé inteligenci, píše.
Nepřímá vtělenost, nepřímá vnořenost, nepřímá vykonatelnost, a nepřímá rozšiřitelnost jsou zcela odlišné atributy než ty, uvažované v klasickém případě 4E kognice. Avšak i tak můžeme v takovém případě usuzovat z jednání systému přinejmenším na jakousi iluzorní inteligenci, která nabízí iluzi inteligence vzhledem k danému prostředí, založenou na masivní agregaci dat z tohoto prostředí a výběru reakcí, jež závisejí
na současném i minulém kontextu jednání systému. V každém případě jde o jednání odtržené od reálné, bezprostřední kognice. (Mimochodem – tak jednají i lidé, pokud dospějí k rozhodnutí na základě „přemýšlení“.) Iluzorní inteligence je v mnoha případech lepší než žádná inteligence. Otázkou zůstává, jestli součástí takové iluzorní inteligence je i nějaká forma vědomí. Iluzorní vědomí? Úvahy, jestli velké jazykové modely mohou mít vědomí se začínají objevovat v pracích odborníků z oblasti filosofie i umělé inteligence.
Je třeba si uvědomit, že text, který velký jazykový model vygeneruje, je vlastně „umělá moudrost“. Sémantika textu, který model vygeneruje, představuje ony požadované pragmatické, resp. etické hodnoty, a posléze samotný výpočetní akt konstrukce odpovědi odpovídá (resp. měl by odpovídat) „cílevědomému používání znalostí modelu“. „Cílevědomé jednání“ je řízeno dotazem – model generuje text, který nejlépe souzní s odpovědí na daný dotaz.
V reakci na iluzorní inteligenci velkých jazykových modelů můžeme tedy hovořit o iluzorní moudrosti takových systémů. Iluzorní inteligence velkých jazykových modelů současně vysvětluje jejich náchylnost ke katastrofickým selháním, kdy vygenerují vymyšlené informace nebo dělají elementární logické chyby v uvažování. Je tomu tak proto, že odvozovací mechanizmus těchto systému je založen na statistice, nikoliv logice. Systém nemůže v každém případě generovat „pravdivé odpovědi“, protože nemá přístup k vnějšímu světu ani k jiným nezávislým zdrojům za účelem ověřování faktů. Systém může generovat pouze taková fakta, která nejsou ve sporu s jeho naučenými trénovacími daty. Zatím není jasné, jestli je toto tzv. „kecání“ velkých jazykových modelů jejich vlastností, kterou dokážeme pouze minimalizovat, avšak nikoliv zcela odstranit.
Umění se zeptat: jak dostat moudré odpovědi z velkých jazykových modelů
Jakou moudrost můžeme, alespoň v principu, dostat z velkých jazykových modelů? Odpověď na to je vlastně skrytá již v jejich názvu. Proč se velké jazykové modely jmenují tak, jak se jmenují? Čeho jsou to modely? Z předchozí sekce víme, že tyto obrovské modely jsou vlastně implicitní modely našeho světa, zachycené v přirozeném jazyce. Jsou trénované na gigantických množstvích textových dat, které obsahují informace o našem světě – fakta, informace, různé vzory, jazykové struktury a znalosti, a také vztahy mezi nimi. To jim pak umožní získat vědomosti, a dokonce (umělou) moudrost o vnějším světě a generovat text konzistentní s tím, co o něm vědí.
Uživatelé, tj. my – lidé, získáváme z nich tyto vědomosti pomocí dotazů, tzv. promptů. Je jisté, že čím přesnější dotaz, čím lépe formulovaný požadavek, tím přesnější a výstižnější odpověď systému můžeme očekávat. Abychom takové dotazy efektivně formulovali je dobré vědět, alespoň v hrubých rysech, jak velké jazykové modely fungují. To nám umožní při sestavování dotazů vycházet vstříc potřebám modelu a umožnit tak jeho efektivní odpovídání na dotazy. Za tím účelem uvedeme velmi zjednodušené vysvětlení jejich činnosti na vysoké úrovni, oproštěné od méně podstatných detailů.
Základní datová strukturu, nad kterou modely pracují, je obrovská síť. V jejích uzlech jsou uloženy informace o slovech a větách. Spojení mezi uzly reprezentují vztahy mezi uzly, které se budují pomocí učení. Na tuto síť můžeme pohlížet jako na analogii mozku: uzly jsou mozkové buňky – neurony, propojení mezi nimi odpovídají synapsím. V technických termínech se jedná o umělou neuronovou síť.
Neuronová síť se učí prostřednictvím čtení textů z internetu. Vztahy mezi slovy a větami jsou vyjádřeny pomocí spojení mezi uzly. Každému spojení je přiřazena jeho váha. Váhy jsou vektory, které charakterizují sémantické vlastnosti vztahů: reprezentují jejich sílu, druh a vlastnosti; budují se a modifikují v průběhu učení. Je to proces absorpce veškerých znalostí a moudra z knih a webových stránek.
Když už je neuronová síť naučená, může být systém požádán o odpověď na daný prompt. Systém generuje odpověď slovo za slovem, jedno po druhém. Generace každého dalšího slova závisí na celém promptu, a na částečné odpovědi, kterou systém do té doby vygeneroval, a samozřejmě i na tom, co se model naučil ze svých trénovacích dat. Za tím účelem model obsahuje veledůležitý mechanismus, který je srdcem jeho „inteligence“: mechanizmus pozornosti.
Tento mechanizmus slouží modelu pro výběr, predikci, soustředění se na slovo, které bude model jako další generovat. Jde o to, aby se vybralo takové další slovo, které přispěje k „správné“ odpovědi, která by z hlediska znalosti uložených v síti co možná nejlépe reagovala na daný prompt. Přitom se vynechají slova, která jsou pro tento účel nepodstatná. (Tato ostatní slova však mohou být důležitá z hlediska formulace gramaticky správné odpovědi.)
Mechanismus pozornosti je také realizován pomocí neuronové sítě. Pro svoji činnost využívá váhy mezi spojeními uzlů, které vyjadřují sílu (míru pravděpodobnosti výskytu) vztahu mezi slovy promptu a slovy částečné odpovědi. Mechanismus pozornosti pak vybere slovo, které se s velkou pravděpodobností „hodí“ k prodloužení již generované částečné odpovědi a také ke slovům z promptu. Tím se zabezpečí, že systém generuje sémanticky nejlépe odpovídající a gramaticky korektní odpověď.
Systém současně monitoruje celý proces sledováním míry podobnosti (opět pomocí vah) mezi promptem a doposud generovanou odpovědí. Začne-li tato míra klesat, systém „ví“, že negeneruje relevantní odpověď a vyzve pozornostní mechanizmus, aby zaměřil pozornost na jiné části promptu. Tento proces monitorování míry podobnosti a využívání pozornostního mechanismu se opakuje do té doby, než je vygenerovaná kompletní a smysluplná odpovídající odpověď.
Monitorování míry podobnosti a využívání pozornostního mechanismu je zásadní inovace, která stojí v pozadí úspěchu současné generativní umělé inteligence. Toho si nejsou vědomi ani někteří odborníci na IT, kteří se domnívají, že model má přístup ke všem trénovacím datům, ze kterých se učil, a může je použít k vyhledávání relevantních informací v obrovské databázi. Tak to samozřejmě není, velký jazykový systém pracuje s naučeným modelem znalostí o trénovacích datech a odhalenými vztahy mezi nimi. Jazykový model je daleko menší než jeho trénovací data. Na dotazy odpovídá konstrukcí zcela nových odpovědí.
Právě popsaný princip práce velkých jazykových systémů je známý už řadu let a lze jej považovat za výsledek matematické a inženýrské invence. Avšak skutečnost, že začíná skvěle fungovat až „ve velkém“, na úrovni masivních dat a s nasazením obrovské výpočetní síly, považují někteří experti na umělou inteligenci doslova za vědecký objev.
Z právě popsaného principu fungování takových modelů je zřejmé, že uživatel může ovlivňovat kvalitu jeho odpovědí jediným způsobem – a tím je formulace promptu. Proces zpřesňování formulace promptu za účelem získání co nejvýstižnější odpovědi se v angličtině jmenuje „prompt engineering“, což se dá přeložit jako „konstrukce nápovědy“, anebo jednoduše „nápověda“.
Účelem nápovědy je dodat modelu – přesněji jeho pozornostnímu mechanismu – výstižné a stručné výrazivo, jež umožní modelu lepší porozumění promptu a generování srozumitelné odpovědi. Jazyk promptu proto budiž jednoznačný a střízlivý pro dosažení objektivní reakce. Často pomůže, zmíníme-li v dotazu pojmy, o kterých předpokládáme, že by se mohly vyskytovat v odpovědi. Intuice, emoce a subjektivní zkušenost jsou další záležitosti, které můžeme uvést, pokud jsou to pro získání odpovědi relevantní faktory. V rámci promptu můžeme zmínit i etická dilemata, které bychom chtěli v kontextu promptu vyřešit, sociální aspekty apod. – zkrátka veškeré okolnosti, kterým by model v rámci své umělé moudrosti možná nemusel věnovat pozornost. To způsobí, že model se při konstrukci odpovědi soustředí i na tyto aspekty. Také je dobré specifikovat formát, formu a styl odpovědi – seznam zarážek, tabulka, úvaha, zdvořilá žádost, populární nebo odborný text, alternativy apod.
Nejlepší způsob, jak se naučit formulovat účinné prompty pro dosažení přesných a relevantních odpovědí, je nebát se experimentovat s jejich různou podobou.
V případě velkých jazykových modelů platí pro určité typy dotazů, že v dobře formulované otázce se často skrývá návod na její odpověď.
Poslední dobrá rada je položit stejnou otázku různým modelům se stejným obsahovým zaměřením. Je překvapivé, jak se mohou odpovědi lišit z hlediska jejich relevantnosti a srozumitelnosti, anebo do jaké míry se mohou shodovat.
Můžeme umělé inteligenci důvěřovat?
Co když nás umělá inteligence oklame, cíleně, kdyby byla za tímto účelem zkonstruovaná, anebo „nechtěně“, kdyby byla chyba v její konstrukci? V tom druhém případě hovoříme o nechtěných vedlejších efektech. To, samozřejmě, může napáchat velké škody. Někteří lidé – a často i odborníci na umělou inteligenci – dokonce varují, že neřízený rozvoj umělé inteligence může existenčně ohrozit přežití lidské civilizace. Je to pravda? Na jakých argumentech jsou taková tvrzení založena?
Skutečnost je totiž taková, že neexistuje efektivní postup (algoritmus), jež by pro jakýkoliv systém umělé inteligence rozhodnul, buď empiricky, na základě testování jeho chování, anebo teoreticky, na základě znalosti jeho popisu, zda bude za každých okolností bezpečný – v souladu s „lidskými hodnotami“.
Mezi takové hodnoty počítáme i nemožnost ohrožení našeho přežití. Důvod v prvním případě je banální – inteligentní systém v případě jeho testování by totiž mohl předstírat, že je „hodný chlapec“, ale potom by se už choval, jak se mu zlíbí. Ve druhém případě je důkaz shora uvedeného tvrzení hluboký poznatek z teorie vyčíslitelnosti, jehož idea pochází od samotného A.M. Turinga, „vynálezce“ moderních počítačů a vizionáře umělé inteligence.
To na první pohled vypadá beznadějně, a proto se zdá být rozumné, nepouštět se do konstrukce takových systémů. Podívejme se však na předchozí tvrzení podrobněji.
Toto tvrzení totiž neříká vůbec nic o tom, že pro libovolně daný systém umělé inteligence nemůže existovat důkaz, že systém bude za každých okolností bezpečný. Jinými slovy, může se klidně stát, že pro daný systém existuje důkaz, že je důvěryhodný, avšak tento důkaz bude „fungovat“ jen pro tento jeden systém. Jestli takový důkaz nalezneme záleží, kromě naší inteligence, na složitosti daného systému. Např. pro již zmiňované automatické dveře je to zřejmě možné, pro samořídící vozidlo pravděpodobně také. Ale co se složitějšími systémy, jakými jsou např. velké jazykové systémy, o super-inteligentních systémech ani nemluvě?
Zde se nám totiž staví do cesty další překážka, a tou je neprůhlednost takových systémů. Vzhledem k tomu že takové systémy se budují pomocí učení, což je stochastický, evoluční proces, my ani nevíme, proč přesně takové systémy v konkrétních případech fungují. Jsou to pro nás „černé skříňky“. Vzhledem k astronomickému počtu situací, ve kterých mají takové systémy fungovat, není možné specifikovat jejich chování za všech okolností, které se mohou vyskytnout. Tím pádem ani není možné předepsat, jak se mají chovat za všech okolností. Toto opět vypadá jako ultimativní argument proti vývoji obecných systémů umělé inteligence (AGI), anebo super-inteligentních systémů.
Beznadějnost úkolu „zkrotit“ umělou inteligenci vypadá jako očividná ještě i z následujícího uhlu pohledu. My – lidé, vládnoucí jistou inteligencí, jsme postaveni před úkol, najít mechanismus, jenž by zabránil, za každých okolností, daleko vyšším inteligencím vymknout se naším zájmům. Je to vůbec principiálně možné, aby „nižší inteligence“ v tomto smyslu usměrňovala, jaksi na dálku, do budoucna, chování „vyšší inteligence“? Známe v přírodě podobný případ?
Podle Ilyu Sutskevera, šéfa výzkumu fy OpenAI, jsou takovým případem děti-nemluvňata. Jejich rodiče, daleko inteligentnější entity než nemluvňata, se starají velmi intenzivně o své potomstvo. Takže to nějak jde, vštípit, imprintovat tuto povinnost, starat se o blaho nižší inteligence, do fungování inteligence vyšší. Naše neschopnost odhalení mechanismu, jenž je za takovým chováním, je obrovskou překážkou na cestě k všeobecné umělé inteligenci.
Pro uklidnění obav z existenčního ohrožení lidstva umělou inteligencí je potřebné si uvědomit, že současná umělá inteligence je tomu, aby nás existenčně ohrozila, na hony vzdálená. Jednoduše to nejde, protože může maximálně ovládnout mysl některých důvěřivých lidí, ale žádné zkázonosné stroje. Sama nekoná ani o ničem nerozhoduje. Namísto obav z umělé inteligence je nutné napřít naše osvětové úsilí na vysvětlování skutečných benefitů umělé inteligence, ve vztahu k našemu blahobytu, a informovat pravdivě o výzkumném úsilí v oblasti umělé inteligence orientovaném na řešení problému souladu umělé inteligence s lidskými zájmy. Je celkem možné, že jednou, v budoucnosti, takový úkol nám pomohou vyřešit samotné systémy umělé inteligence. To je další důvod pro výzkum, vývoj a používání takových systémů.
Jak to všechno dopadlo?
Vraťme se nyní k naším dvěma motivačním otázkám ze začátku reportu. Zvážením naších předchozích výsledků a úvah jsme dospěli k době zdůvodněným odpovědím, jaké jsme slibovali v jeho počátku:
Umělou inteligenci rozvíjíme za účelem tvoření a rozvíjení nástrojů pro generování umělé moudrosti.
Účelem používání umělé inteligence je generovat moudrá rozhodnutí a moudré chování pomocí vzájemné spolupráce mezi lidmi a automatickými prostředky.
Dobrovolně se vzdát takových nástrojů by bylo nerozumné. Je třeba hledat cesty, jak takové nástroje rozvíjet, s nimi nažívat a jak je bezpečně používat. Jedno řešení je nasnadě: spolupráce lidí s takovými systémy. Řešit problémy společně, ve vzájemné dohodě. Nedovolit jedné straně činit zásadní rozhodnutí bez konzultace s druhou stranou. Dávkovat rozvoj takových systémů jako v moderní teorii etapovitého kognitivního vývoje, která pojednává o povaze a rozvoji lidské inteligence postupným rozšiřováním znalostních domén. Nevyvíjet další, „vyšší“ verze moudrých systémů, pokud nebude jasné, že stávající verze jsou v souladu s našimi hodnotami. Ideu takové spolupráce dobře vystihuje rodičovská metafora: vztah lidí k umělé inteligenci by měl být jako vztah mezi rodiči a jejich dětmi: když jsou děti malé, starají se o ně, a vychovávají je rodiče; když jsou děti dospělé a rodiče staří, pečují o ně, a ctí je jejich potomci
Tímto způsobem se stane lidská a umělá inteligence neporazitelnou dvojicí, která umožní formování naší budoucnosti podle našich představ.
Je nutné si uvědomit, že na moudrost generovanou v rámci spolupráce mezi lidmi a umělou inteligencí musíme uplatňovat stejná kritéria jako na umělou moudrost z části 3: totiž aplikovat veškeré znalosti na jednání směřující k cílevědomému vytváření pragmatických hodnost pro kultivaci naší společné budoucnosti, za současného dodržování etických hodnot.
Z filozofického hlediska a z pohledu metodologie, umělá moudrost představuje kvalitativní posun ve výpočetním paradigmatu používaném v umělé inteligenci, a sice od pohledu na výpočty jako procesy generující znalosti směrem k procesům generujícím a využívajícím moudrost. Koncept umělé moudrosti, vedle lidské moudrosti, se stává novou, a pravděpodobně finální metou lidského snažení.
Rozhodnout se pro vývoj a používaní nástrojů umělé inteligence pro generování umělé moudrosti vyžaduje kuráž, moudrost, znalost problematiky a víru ve schopnosti lidí ve spolupráci s umělou inteligencí.
Právě uvedené tvrzení neznamená, že se vzdáme regulace vývoje v oblasti AI, tak jak navrhuje Rada EU, která přijala společný postoj – Akt o umělé inteligenci. Jeho cílem je zajistit, aby systémy umělé inteligence, které budou uváděny na trh EU a používány v EU, byly bezpečné a byly v souladu se stávajícími právními předpisy o základních právech a hodnotách EU. Podobné iniciativy existují v USA i jinde. V rámci takových regulací je společný rozvoj inteligentních systémů velkou výzvou, avšak její přínosy budou stát za to. Budou znamenat obrovský, v lidské historii nikdy předtím nevídaný pokrok, srovnatelný s ovládnutím ohně a svým dopadem překonávající průmyslovou revoluci. Moudré systémy umožní lépe a odpovědněji posuzovat vývoj v různých oblastech života lidí, politiky, geopolitiky, dělat lepší rozhodnutí, pomáhat při řešení globálních a jiných praktických problémů a v konečném důsledku žít smysluplnější životy. Stanou se onou zdviží, zmiňovanou v názvu kapitoly, do naší budoucnosti. Znalostní společnost se transformuje na moudrou společnost, societas sapientiae, kterou charakterizuje cílevědomé využívání moudrosti.
Umělá moudrost bude současně představovat společně s přirozenou moudrostí trvalý a smysluplný odkaz naším současníkům i potomkům a bude zvyšovat pravděpodobnost a kvalitu našeho a jejich přežití v proměnlivých budoucích časech a neznámých místech ve Vesmíru.
A jaká je odpověď na Ackoffovu predikci ze závěru 2. sekce ohledně automatů generujících moudrost? Pokud se pod pojmem moudrosti myslí striktně moudrost lidského typu, tak možná má Ackoff pravdu: stroje samotné pravděpodobně nikdy nebudou mít vlastnosti empatie, intuice anebo vědomé zkušenosti, jaké mají lidé. Naše úvahy však naznačují, že umělá moudrost, vzhledem ke své univerzálnosti a šíři problémového prostoru, který má umělá moudrost potenciál pokrýt, bude lidskou moudrost ve většině oblastí předčit. Ale již zmiňovaný pár lidské a umělé moudrosti společně odpovídá naší představě o ideální moudrosti jako prostředku pro formování a naplňování našich ideálů. Taková vize moudrosti posouvá známý Aristotelův výrok „Všichni lidé od přirozenosti touží po vědění“ do ještě vyšší roviny: „Všichni lidé od přirozenosti touží po moudrosti“.
Závěr
Systémy umělé inteligence generující moudrost jsou fundamentálně nové objekty, s jakými se lidstvo doposud nesetkalo. Jejich příchod znamená milník v historii lidstva, protože přináší novou a bezprecedentní formu inteligence, jež bude současně umělá a moudrá a bude komplementární a současně alternativní k naší přirozené inteligenci. Budou daleko lépe rozumět objektivnímu světu prostřednictvím většího množství jejich „smyslů“, než mají lidé, budou se rychleji učit, budou kreativnější. Tyto systémy budou uvažovat a argumentovat podobně jako lidé, avšak vzhledem ke svým zmnoženým kognitivním schopnostem přesahujícím schopnosti lidské se budou opírat o data, informace, znalosti a moudrost, které nebudou nikdy přístupná lidem bez těchto technologií. Doslova se stanou studnicí veškeré moudrosti, kamenem mudrců a svatým grálem lidstva.
Tento splněný sen lidstva však bude mít své stinné stránky.
Pokud se nám nepodaří uspokojivě vyřešit problém souladu systémů generujících moudrost s lidskými hodnotami, bez jejich spolupráce s námi ztratíme své dominantní postavení mezi inteligentními entitami. Budeme konfrontování s Faustovým dilematem – potenciálním kompromisem mezi dobrodiním umělé moudrosti a nebezpečím spojeným s jejím vývojem a používáním. To může znamenat naše existenční ohrožení.
Kterou cestu si zvolíme? Jak se rozhodneme?
A jsme vůbec připraveni se rozhodnout?
Literatura
Ackoff, R.L., From Data to Wisdom - Presidential Address to ISGSR, June 1988, J. Applied Systems Analysis 18 (1989), s. 3-9.
Newen, A., De Bruin, L., Gallagher, S. (eds). The Oxford Handbook of 4E Cognition, Oxford Library of Psychology (2018; online edition, Oxford Academic, 9 Oct. 2018).
Wiedermann, J., van Leeuwen, J., From Knowledge to Wisdom: The Power of Large Language Models in AI. Technical Report UU-PCS-2023-01, červenec 2023.
---
Původně vyšlo v Proč se nebát umělé inteligence. Jota, Praha 2024. Autoři knihy Proč se nebát umělé inteligence? nabízejí střízlivý a odborně podložený pohled na současný stav a perspektivy umělé inteligence (AI). Čtenář se ve srozumitelné podobě dozví, na jakých technologických základech AI stojí, jaká je její historie a jak probíhá zpracování přirozené řeči ve velkých jazykových modelech. Kniha rovněž ukazuje, jak aplikace AI už dnes slouží v průmyslu, zdravotnictví, robotice či v oblasti kybernetické bezpečnosti a jak konkrétně je možné AI využít například ve státní správě či ve službách. Řada příspěvků je věnována filozofickým úvahám o roli a možnostech umělých strojů, etice a právu při jejich využívání.

Report je ke stažení zde.
Cookies
